概要
EPSSやKEV Catalogを有用に使うプロジェクトが最近出てきました。
これらについて内容を確認し、どのように使えるか、同様なSSVCとどう違うかを見ていきます。
- CVE_Prioritizer
- SploitScan
Exective Summary
- EPSS, KEVのデータ特性を考える必要がある
- EPSSは機会のみ、KEVは機会と脆弱性を示す
- 当該プロジェクトは使いやすく、CVSSのみで判断している組織は、CVE_Prioritizerをまずは使ってみるのが良いかもしれない
- 当該プロジェクトは システム固有/事業に対するリスク を考慮していないため、SSVCとは異なった観点である
- [PR]SSVCを搭載したFutureVulsも検討してね[/PR]
EPSSとKEV Catalogの概要
EPSSは、別途記事やインターネット上での解説を参照して下さい。
おおよそ以下のようなものです。
- FIRSTで管理されている
- https://www.first.org/epss/
- オリジナルモデルはBlackhat2019で発表され、EPSS SIGが2020年04月にFIRSTで結成された
- modelのアップデートは、過去3回行われている
- 提供データ
- 今後30日間に観察される悪用の確率の日時推定値で、0.0-1.0の値を取る(状況によりPercent表示される)
- 脆弱性が発生してからの経過日数、CVSS Metrics、公開されているExploit Code、攻撃的なセキュリティスキャナの情報、などを組み合わせている
- 例えば、1.0(=100%)なら確実に脆弱性が悪用されることを示し、0.0(0.00%)であれば悪用される確率は、ない
- 数値有効桁数については元データでも揺らぎが多いので、あまり気にしてはいけない
- 悪用される確率を提供しているのであり、リスクを示しているわけではない
- 原則として、リスクは
機会 x 脆弱性 x 資産で示され、その中の1つを示している
- 原則として、リスクは
- 以下の2つのデータを提供する
- Probability(=EPSS Score)
- 今後30日間でその脆弱性が悪用される可能性
- Percentile:
- EPSS Score全体での相対位置
- EPSSに記録されている脆弱性の、全体の何%の位置にいるかを示す
- Probability(=EPSS Score)
- 今後30日間に観察される悪用の確率の日時推定値で、0.0-1.0の値を取る(状況によりPercent表示される)
- 利用方法
KEV Catalog(Known Exploited Vulnerabilities Catalog)も、以下の通りです。
- CISAで管理されている
- 概要
- 「実際に悪用されている脆弱性の信頼できる情報源である既知の悪用された脆弱性」をまとめたカタログ
- EPSSと違い、確率ではなく、 既に悪用されている ことに留意
- ransomwareで悪用されているかを示す項目がある
- 提供データ
- WEBもしくは CSV/JSON で提供されている
- cveID, vendorProduct, product, vulnerabilityName, shortDescription, RequiredAction
- dateAdded, dueDate
- データ追加日と、対応期日(米国内における)
- knownRansomwareCampaignUse
- WEBもしくは CSV/JSON で提供されている
- 利用方法
各プロジェクトの概要
CVE_Prioritizer及びSploitScanについて、実際に動作させてみました。2024-02-29時点の情報です。
本記事末尾に、Dockerでの構築方法を残しておきます。
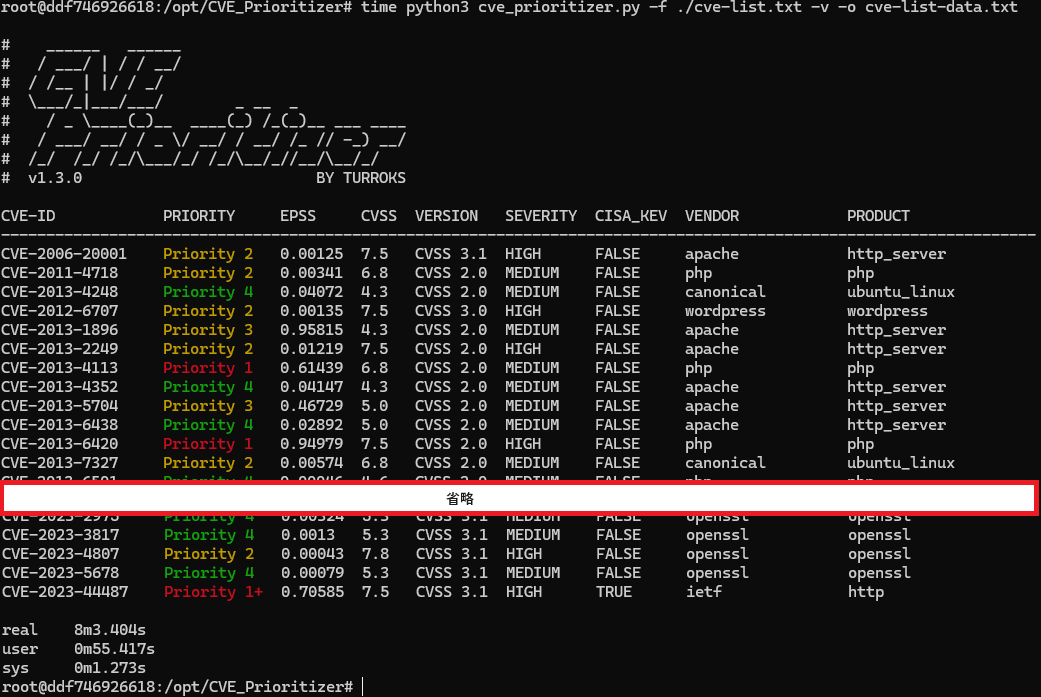
CVE_Prioritizer
概要
https://github.com/TURROKS/CVE_Prioritizer
READMEに概念等が書いてあり、CVSS/EPSS/KEV をどのように組み合わせれば良いかが、分かりやすく提示されています。
- EPSSの説明もわかりやすいですね
- 逆に KEV Catalog や CVSS BaseScore については、説明としてはあまり触れられていません
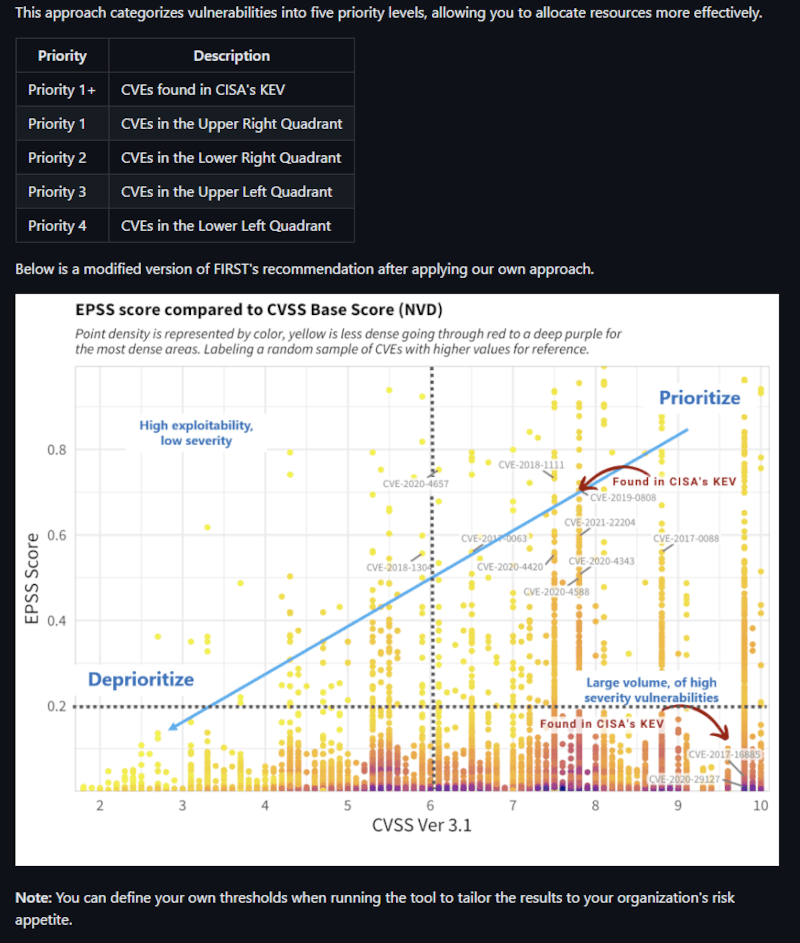
- どのようなアプローチなのかが明確に示されています。
- EPSS / CVSS BaseScore のグラフで、右上/右下/左上/左下の順で順位付けをする
- また、KEVを優先する(”既に悪用が確認されたもの”なので、確定情報として利用するようだ)
- 閾値は、CVSS BaseScoreは
6.0、EPSSは0.2としている- 閾値は、Firstの推奨事項と経験に基づいて決定している、ようだ
We have refined the prioritization thresholds based on FIRST's recommendations and our own experience.
- 閾値は、Firstの推奨事項と経験に基づいて決定している、ようだ
使用感
アプローチとしてはよさそうに感じました。
- CVSS/EPSS/KEVを組み合わせることで、優先順位付けを支援するツール
- KEV Catalogを優先するのは、妥当だと感じます
- EPSS/CVSS のグラフを4事象に分けて右側を優先対応する、というのも妥当だと感じます
- 提示されている閾値も調整可能なようで、必要に応じて変更できそうです
アプリケーションとしてみた場合は、業務で使うことはできそうだ、という感じです。
-vオプションで、判定で利用したソースが見れるのは良いですね- CVE-ID, EPSS, CVSS(Score, Version, Severity), CISA_KEV(True/False)
- NVDに対してAPIアクセスで値を取るため、時間とアクセス回数制限が問題になる場合がありそうです
- 474件のCVEリストを渡したところ、8分程度掛かる
- API-keyを登録してあっても、多数のクエリを投げた場合は制限にかかる恐れがある
全体として、対象の脆弱性が少ない状況であれば、十分に判断の助けになるのではないか、と感じました。
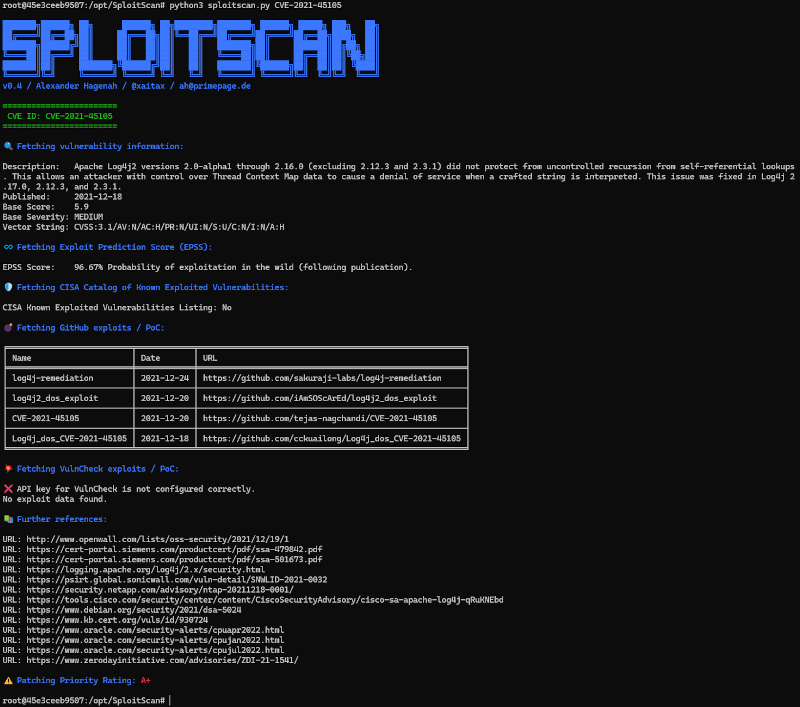
SplitScan
概要
https://github.com/xaitax/SploitScan
パッチ優先順位付けという目的はCVE_Prioritizerと同じですが、PoC Exploitも利用する点が違います。
- CVE, EPSS, PoC Exploit, KEVを利用し、VulnCheckとも統合しているようです
- CVE_Prioritizerのモデルに影響を受けている、と記載されています
- Exploitを処理するための機能が強化されている
- 優先順位付けは、ほぼ同じ優先度で表示される(CVE_Prioritizerは1+/1/2/3/4 だが、SploitScanは A+/A/B/C/D)

使用感
これも、CVE_Prioritizerと同様に、アプローチとして良さそうに感じました。
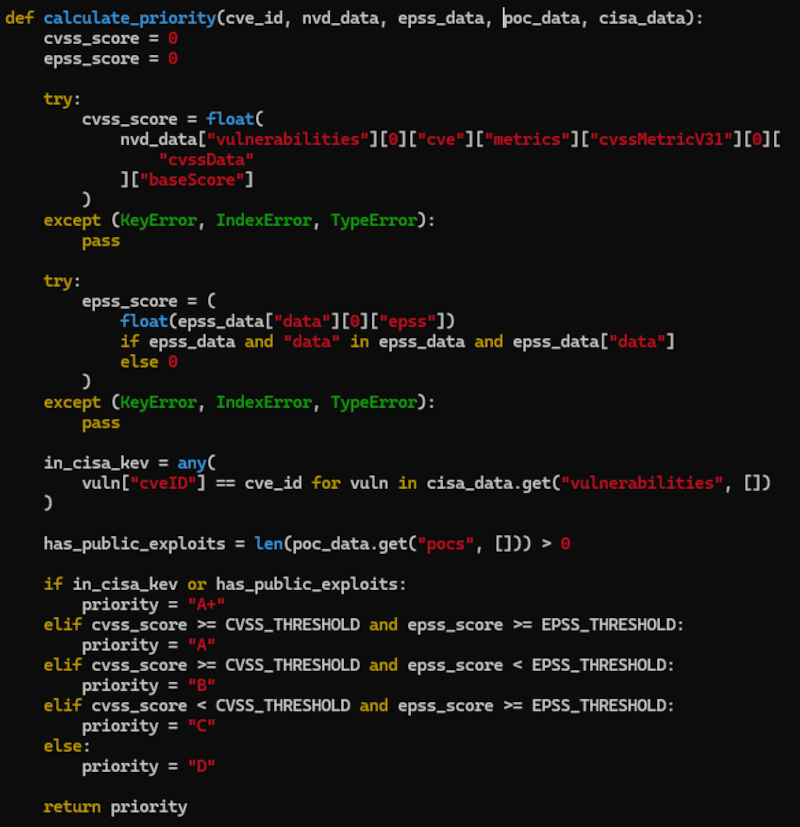
- 攻撃される可能性について、CVE_PrioritizerはEPSSを利用しているが、SploitScanはExploit情報も利用しているようだ
def calculate_priority(cve_id, nvd_data, epss_data, poc_data, cisa_data):で利用している- public exploitがあると、A+になる?
- 多量のCVE-IDを処理することはできない
- CVE_PrioritizerのようにCVE-IDのリストを渡すことはできず、スペース区切りで渡す必要があります
- そして100個程引数に渡すとエラーになっていましたが、単独でもエラーになったので、もしかするとNVDのAPIアクセス回数制限かもしれません
- UIは人間には優しいけど、多数のCVE-IDを使うと疲れてしまいそう
- あくまで総合的な調査で使い、残存脆弱性一覧をぶち当てる使い方ではないと思われます
考察
CVE_PrioritizerとSploitScanでのデータの取り扱いと、同様な優先順位付け基準であるSSVC(Stakeholder-Specific Vulnerability Categorization)との違いなどを考察します。
各プロジェクトについて
両プロジェクトとも、脆弱性それ自体の危険度と、攻撃に利用される可能性、の2点で対応優先度をつけています。そのため、比較的大規模環境で求められる「( 事業に対する )リスク」という観点では少し不足しているように感じるかもしれません。とはいえ、管理対象規模などを考えれば、EPSSやKEV Catalogなどを活用するという点では非常に重要であり、EPSS/KEV/CVSS/Exploitをどう考えるか、のモデルケースになると思われます。
また、KEV Catalogについては最優先の判定になるようです。
CVE_Prioritizerは、シンプルで、既存の脆弱性管理にも組み込みやすいかもしれません。CVE-IDをリストで渡すことで、管理している脆弱性の優先度を一旦丸投げすることも可能です。API-Keyにも対応しているので、多量のCVE-IDを投げてもおおよそ大丈夫かもしれません。
SploitScanは、上記CVE_Prioritizerに比べ、PoC Exploitの情報収集の点で強みがあります。しかしながら多数のCVE-IDを渡すのは、API-Keyが現時点で非対応であることや、引数でしかCVE-IDを渡せない点で、脆弱性管理している多数のCVE-IDを渡すのは難しいかもしれません。しかしながら、別途選別したCVE-IDであれば、確認のために使っていくという使い方で十分かもしれません。また、PoC Explooitが一つでもあると最優先と判定されるのは、状況により気にする必要があるかもしれません。(2024-02-29時点)
SSVCとの違い
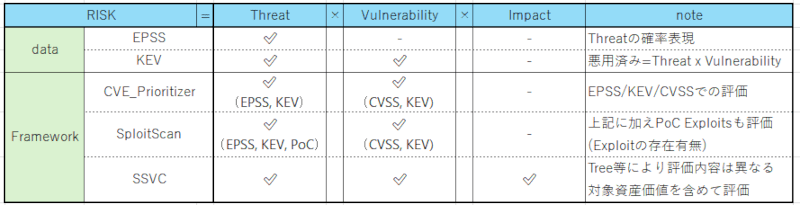
SSVCは、Risk = Threat x Vulnerability x Impact に対応するように設計されています。FuturVulsで利用している Deployer Tree 等は特にそうです。前述のプロジェクトは Impact に関する部分が考慮されていないという点が、SSVCとは異なる点だといえます。
各データやプロジェクトについてRISKという観点からまとめると以下の通りです。
CISA-Coordinator Treeの場合、Exploitation(none/poc/active)でEPSSやExploit有無を利用し、Automatable(no/yes)でKill ChainのSTEP 1-4(1.Reconnaissance, 2.Weponization, 3.delivery, 4.exploitation)を利用し、Technical Impactで技術的な影響度を検討し、Mission&Well-beingで業務影響を勘案したうえで、優先度をつけます。
同様にDeployer Treeの場合は、Exploitation(none/poc/active)、Exposure(small/controlled/open)でインターネットへの暴露状態を示し、Utility(laborious/efficient/superEffective)で攻撃者にとっての便利さを示し、Human Impact(low/medium/high/veryhigh)で安全とミッション(企業活動)への影響を勘案し、優先度をつけます。
impactに関する検討がなされない点は、状況により許容できると考えられます。大規模複数環境であれば一律のactionを設定することは難しい場合も多く、Impactにより対応の濃淡を環境内でつけることができます。また、コンピュータ系サービスを主業務にしていない業態の場合、システム停止時のImpactがコンピュータ系サービスとは異なることもあります。金融等では 停止=業務停止=損害 迄かなり近いことになりますが、例えば 他の業種であれば手動オペレーションで事業へのImpactをある程度低減できる(完全にITシステムに依存しているわけではない)という場合もあります。Impactの情報を定義するということは、第三者の情報ではな自ら決定する部分も増えます。ThreatやVulnerabilityはCVSSやEPSSなどの”他者”が提供するデータで定義できますが、Impactに関連するシステムのインターネット露出度やシステムの価値などは”自ら”で決める必要があります。その場合はSSVCを適用することが困難な場合があります。
- 本質的にはそれらをを決めていく過程で自システムへの理解が高まりリスク判断ができるようになるのですが、そのような人員等余裕がある組織ばかりとは限りません。
上記のように、SSVCは主にImpactに関する指標を取り込むことで、脆弱性単体ではなく「事業リスク」という観点で優先度を示しています。
良い/悪い という問題ではなく、観点が異なるということを理解しておく必要があります。
まとめ
EPSSとKEV Catalogの役割は、おおよそ見当つきましたでしょうか。
- EPSSは、攻撃機会の確率のみを提供する
- KEV Catalogは、実際の悪用から設定されているため、攻撃機会と脆弱性の危険度の両方を兼ね備えているとみてよい
- どちらのプロジェクトでも、KEV Catalogにあるものは優先的に対応すべき、という結論に至っている
事業リスクという観点で見ると、CVE_PrioritizerやSploitScanは”Treat x Vulnerability” を示すものです。自組織のシステム状況などを考慮せずに使えるため、CVSS BaseScoreだけで判断している場合は、始めるのは比較的簡単なため、これらを使ってみるのもよいかもしれません。
また、大規模環境であったりSoC/CSIRTがあるような環境であれば、SSVCを利用する方が良いと思われます。大規模ほど”早急に優先的に対応すべき脆弱性”の数は増え、早急に優先的に対応すべきものの中でも再度優先順位をつける必要がある、という状況に対応しやすいと思います。
[PR]弊社FutureVulsではSSVCの機能を実装しており、以下2点を設定するだけで容易に利用可能です(要CSIRTプラン)。
- Exposure: システムがインターネットにどのように露出しているか
- Utility Dencity: 重要情報が集中しているか否か
- Human Impact: システムの事業における価値(インシデントの際の事業影響)
ご興味のある方は、サイトの「サポート」からご連絡ください。
- https://vuls.biz/
- リクエスト内容に、本ブログを参照した旨を記載いただけると幸いです。
[/PR]
お約束の宣伝
弊社は、SSVCをサポートした FutureVuls というサービスを提供しています。もしよろしければサービスページを訪問いただけると助かります。
- https://vuls.biz/
- 必要ならお問い合わせください。その際は”井上の記事を見た”等の記載を頂ければ幸いです。
また、セキュリティコンサル/脆弱性対応コンサルも行っております。ある程度は無償でご相談をお受けすることはできると思いますので、ご興味があればお問い合わせフォームからご連絡ください。
よろしくお願いいたします。
以上
Appendix
ubuntu:latest のイメージ上に、各プロジェクトを展開する例を示します。
- /opt 以下に導入する
- 共有ディレクトリとして、localの
/tmpを conatiner上の/mnt/shareにマウントする/tmpよりは/home/<username>/share等の共有用ディレクトリを用意したほうが良い- ディレクトリはマウントしても、人に対してマウンティングはしない
- エディタとしてvimを入れている
- 使えない方は、
vimtutorでトレーニングするのが良い可能性がある
- 使えない方は、
how2setup CVE_Prioritizer on Dokcer
- https://github.com/TURROKS/CVE_Prioritizer
- 名前はprioritizerは長いので、prioにします。
- NIST API Keyは以下から必要に応じて取得する
1 | $ docker pull ubuntu |
1 | # vi .env |
1 | # # python3 cve_prioritizer.py -l CVE-2018-17189 CVE-2021-45105 -v |
how2setup SploitScan on Docker
1 | $ docker pull ubuntu |
1 | # vi config.json |
1 | # python3 sploitscan.py CVE-2021-45105 |