2024年10月22日から10月25日に神戸にて開催された、CSS 2024 (コンピュータセキュリティシンポジウム2024) / OSSセキュリティ技術ワークショップ(OWS) 2024の企画セッションにてOSS Vulsチームとして発表してきました。
本セッションでは、OSS脆弱性スキャナVulsの開発経験を通じて明らかになった脆弱性スキャナと提供される脆弱性情報に関する課題を共有しました。また、脆弱性スキャナの普及に伴い、セキュリティ担当者が直面する膨大な脆弱性への対処法についても議論しました。具体的には、膨大な脆弱性情報への対応、VEXやReachabilityを考慮したノイズ削除手法、そしてSSVCやKEV、EPSSなどを活用した最新のリスク評価手法について解説しました。
本エントリでは、講演資料とセッションの全ログを公開していますので、詳細な内容にご興味のある方はぜひご覧ください。
脆弱性管理と課題 - OSSの視点から
ここから、上記の資料の各スライドについて説明していきます。
![CSS2024/OWS] 脆弱性管理と課題 - OSSの視点から](https://bcdn.docswell.com/page/PEXVMM887X.jpg)

この講演は大きく三部に分かれています。まず最初に、脆弱性管理のOSSツールについて概観し、我々が開発しているOSS「Vuls」を用いた脆弱性検知の手順をデモします。
次に第二部では、OSS Vulsの開発過程で直面した脆弱性検知における課題を紹介します。ここでは脆弱性情報側の課題と検知ロジック側の課題を中心に共有します。
最後に第三部では、膨大な数の脆弱性とどう向き合っていくのかの展望を示します。前半ではリスクの判断方法について、後半では検知された脆弱性の中から本質的に影響のないものを除去する方法について考えます。

初めまして、shino(篠原)です。OSS Vulsの開発に携わっています。ソフトウェアエンジニアとしてこれまでRADIUS認証サーバやオブジェクトストレージ、WebRTCサーバなどを手掛けてきました。20年以上前、大学院時代に学会発表の機会がありましたが、今回CSS 2024というアカデミックな場で話すことができ、大変ありがたく思っています。
1. 脆弱性管理とOSS

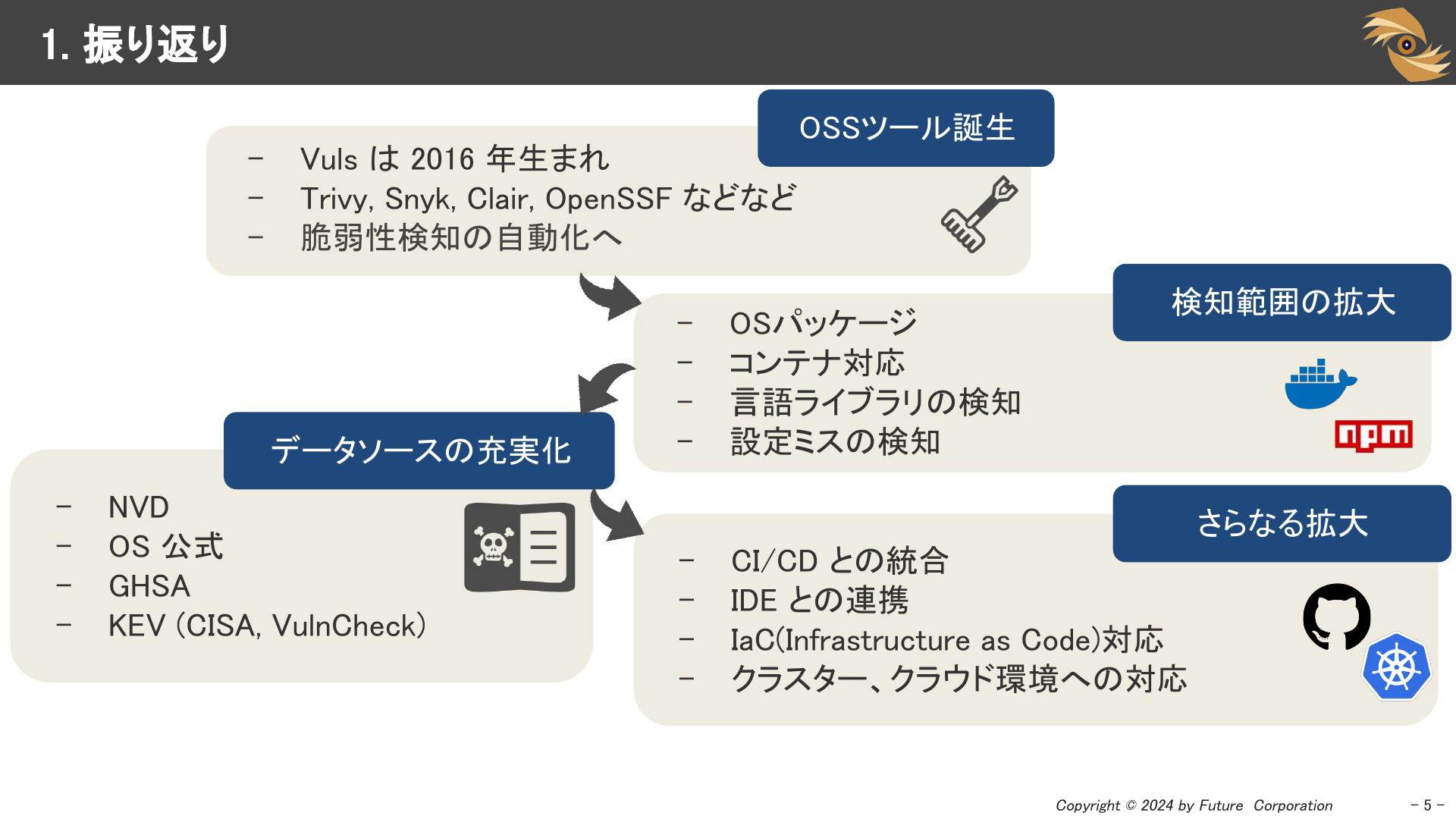
OSSの脆弱性管理ツールの進化を振り返ります。Vulsは2016年に誕生し、それ以降同様のツールが次々と登場し成長してきました。初期はOSディストリビューションのパッケージのみが対象でしたが、現在はコンテナやプログラミング言語のライブラリにも適用範囲が広がっています。また、GHSAやCISA、VulnCheckによるKEV(Known Exploited Vulnerabilities)など、公開されるデータソースも増加しています。
近年ではCI/CDやIDEとの統合が進み、より早期の脆弱性検知が可能になっています。さらに、クラスターやクラウド環境への対応も活発に進んでいます。

脆弱性管理のOSSは多数存在しますが、ここではその一部を紹介します。
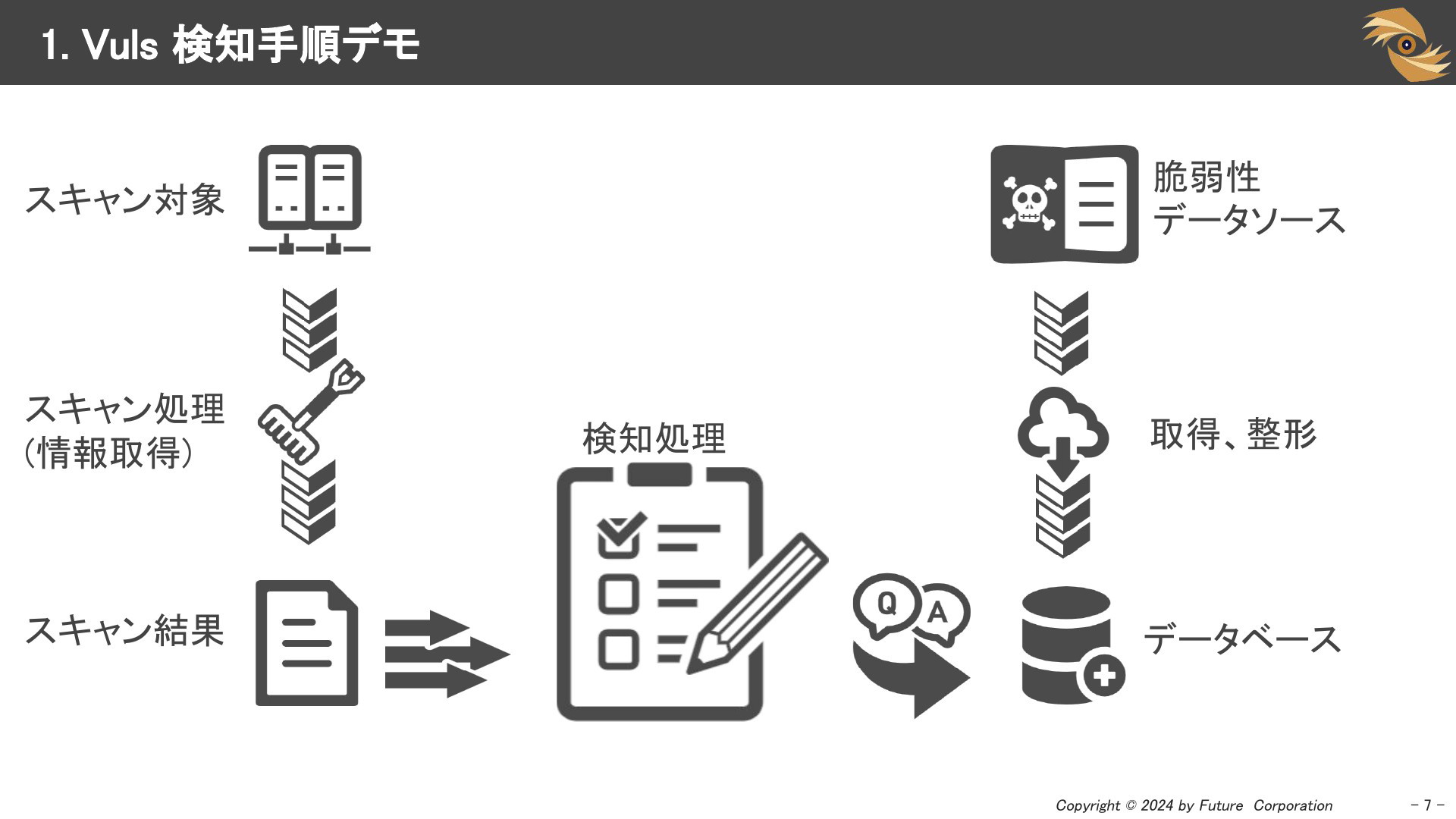
第二部以降の説明に入る前に、Vulsを使った検知のデモを行いました。左の列では、Ubuntu Linuxに対して”vuls scan”コマンドを使い、パッケージリストを取得する「スキャン」処理を行いました。
右の列では、脆弱性情報を取得し、検知しやすい形でデータベースに保存しました。最後に「検知」処理として、取得した情報を突き合わせて影響のある脆弱性をリストアップしました。

今後の課題として、データソースの課題や「膨大な脆弱性への対応」について、第二部・第三部で詳しく解説していきます。
2. 脆弱性検知における課題

この部では、Vulsを開発・運用していくなかで出会った脆弱性検知における課題を主にデータソースの観点から紹介します。

OSS開発を主にやっております、MaineK00nです。
最近は、Vuls検知部分を改善するため、MaineK00n/vuls-data-updateとMaineK00n/vuls2 a.k.a. Vuls Nightlyの開発を頑張っています。

現在のVulsのような脆弱性スキャナにとって、脆弱性情報の量・質はとても重要です。
また、脆弱性情報の内容を十分に利用できるまでは、スキャナの性能を上げることも必要です。
例えば、スキャナがLinux Kernelのバージョンとモジュール情報を収集できても、脆弱性情報にはバージョン情報だけが整理されており、モジュール情報がない場合は、バージョン情報での比較によって影響を判定します。逆に、脆弱性情報がバージョンと影響条件(例えば特定の設定や特定の機能が有効であるかどうか)を提供しても、スキャナがバージョン情報しか取得していなければ、バージョンレベルでしか判定ができません。また、そもそも脆弱性情報が提供されていない場合は、影響を受けるかどうかも不明です。
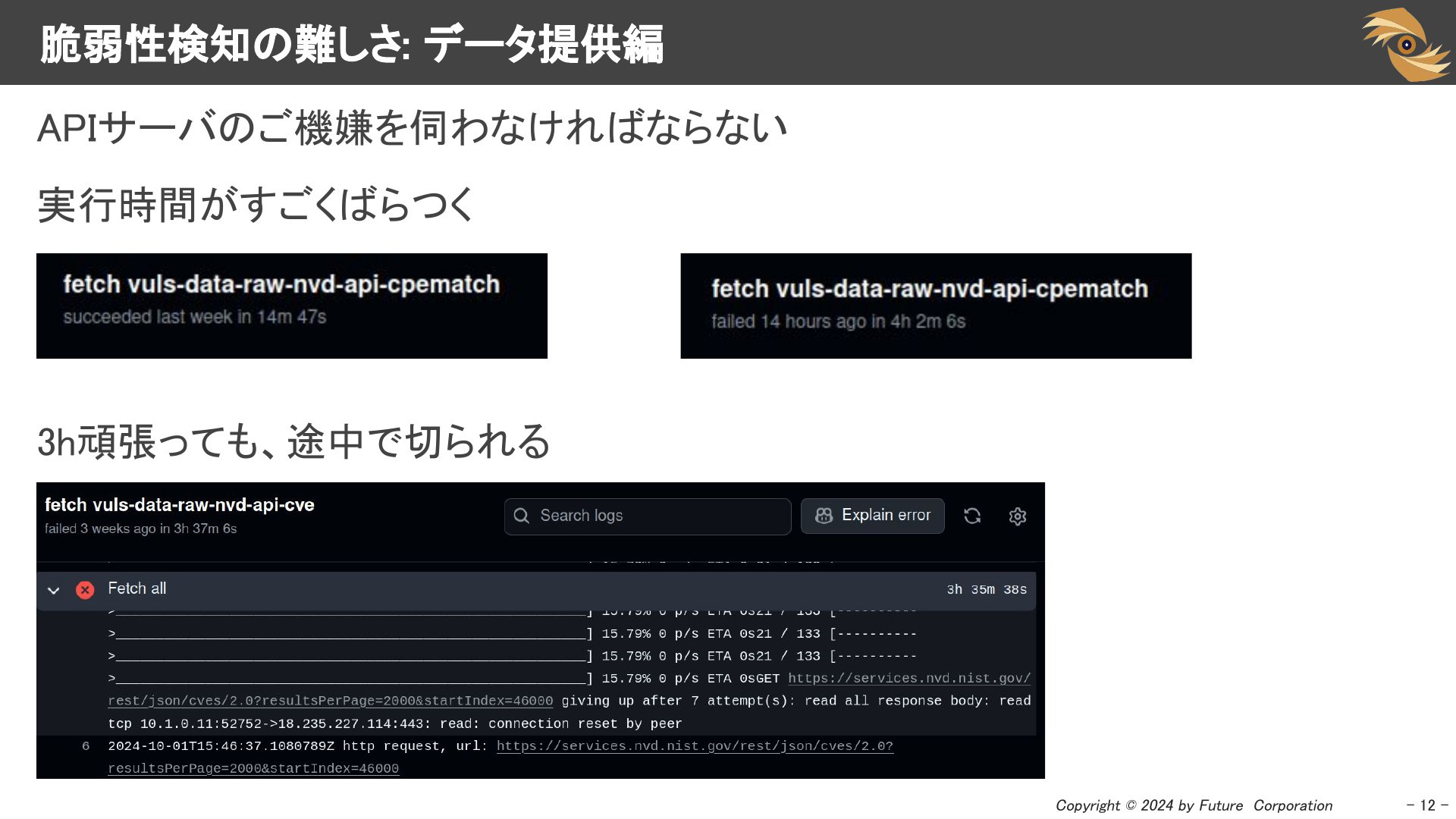
まずは、データ提供に関する課題についていくつか紹介します。脆弱性情報を収集して脆弱性DBを作成する際にも、いくつかの問題があります。特に、NVD API 2.0へ移行した後、その実行時間が不安定になり、脆弱性情報の取得に数時間かかることがあるなど、スキャナのパフォーマンスに大きな影響を与え、運用上の困難を感じていました。
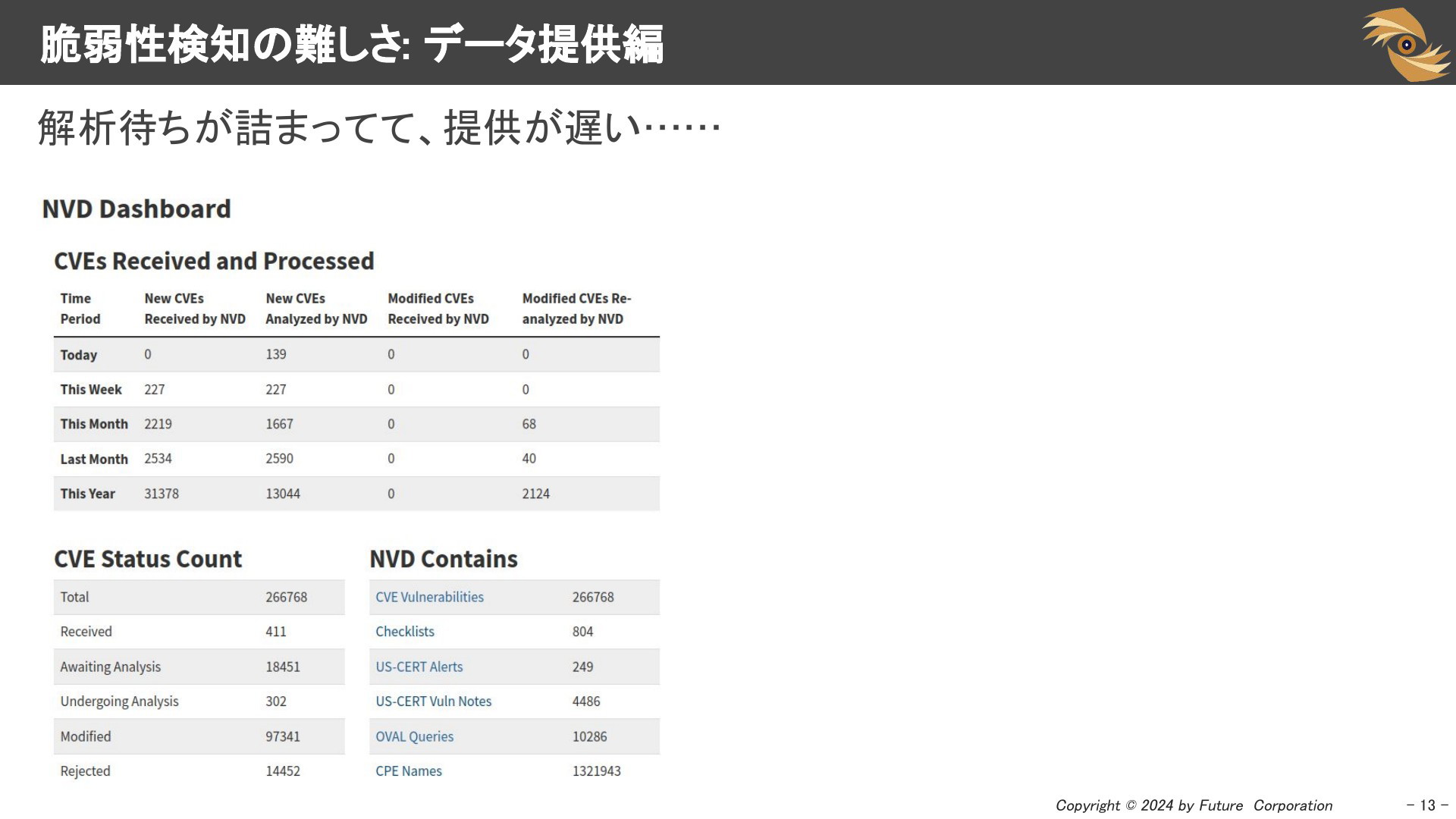
2024年、NVDの解析待ちが詰まっており、非常に問題になっています。NVDにはCVSSスコア、CPE情報など多くの情報が含まれていますが、皆さんはどの情報を特に利用していますか? Vulsでは、CVSSの情報はもちろん、パッケージマネージャ外でインストールしているものに対する脆弱性検知のためにCPE情報を利用しています。しかし、解析待ちでCPEの情報が追加されないため、一部の脆弱性については検知できません。
さて、NVDは以下のように発表しているのですが、実際はどうでしょうか……(アメリカの会計年度は9月に終わるはずですが
In addition, a backlog of unprocessed CVEs has developed since February. NIST is working with the Department of Homeland Security’s Cybersecurity and Infrastructure Security Agency (CISA) to facilitate the addition of these unprocessed CVEs to the NVD. We anticipate that that this backlog will be cleared by the end of the fiscal year.
May 29, 2024: https://www.nist.gov/itl/nvd/nvd-news
NVDは、NVD ダッシュボード を公開していて、解析待ちが何件あるかとか見ることができます。
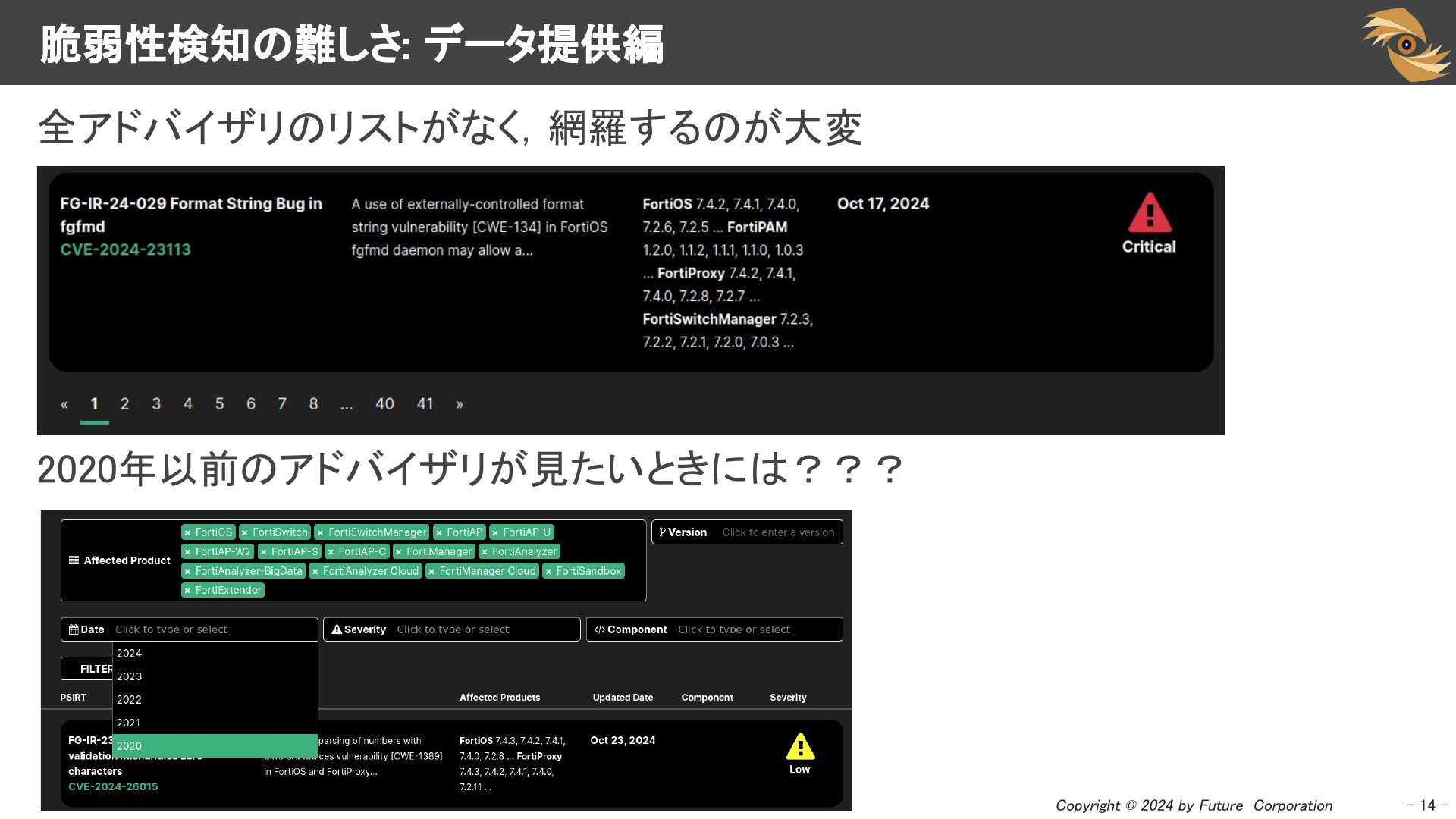
APIの提供がなく、アドバイザリ全体にアクセスするためには、器用にページングしながら見ていく必要があるような提供の形は大変です。
また、度重なる更新によって、過去のアドバイザリへのアクセスが失われてしまうこともあります。
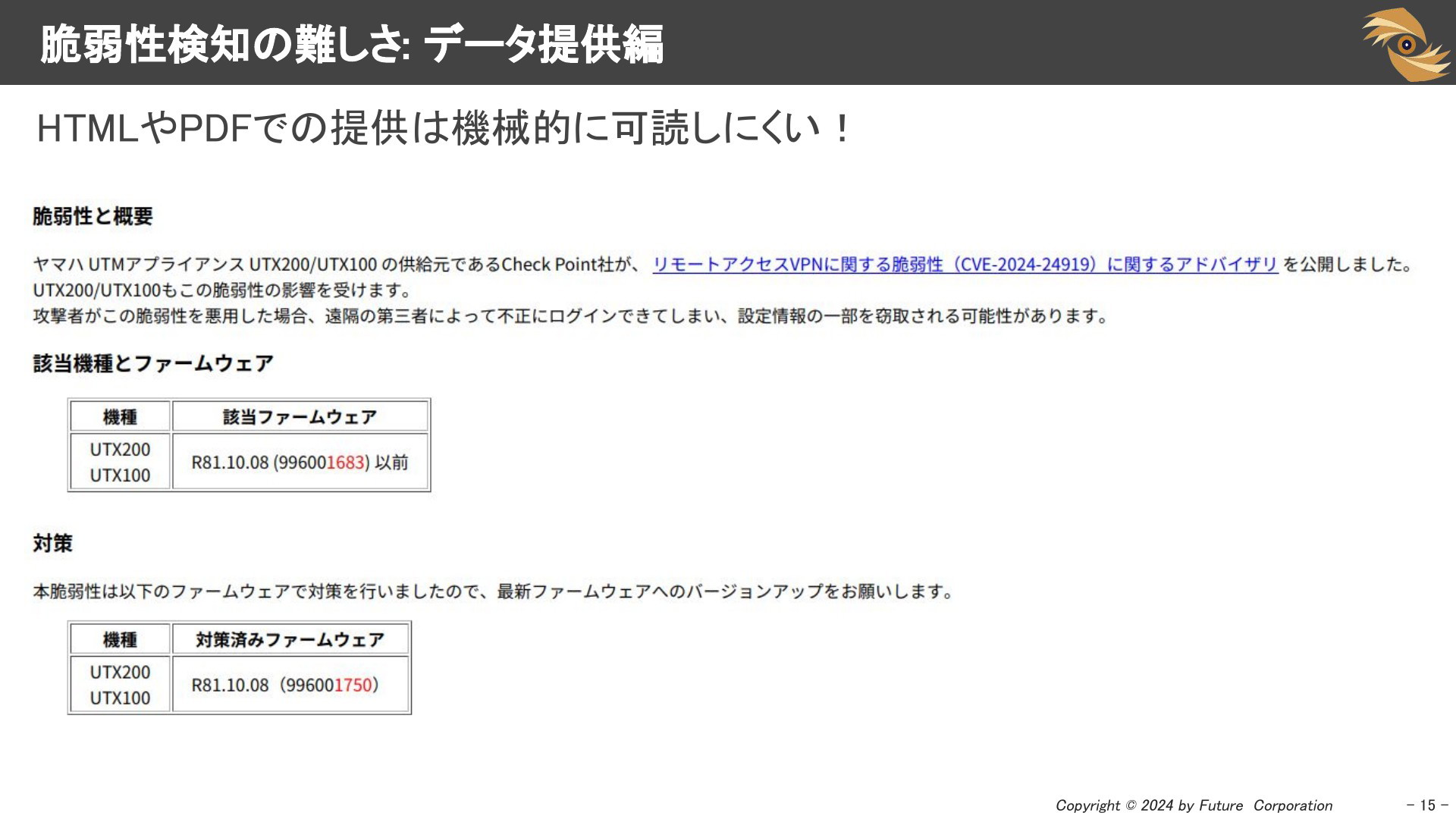
HTMLやPDFでしか脆弱性情報が提供されない場合、機械的に読み取りにくくなります。せめてHTMLでもフォーマットが統一されていれば、まだ対応できる場合もありますが、多くの場合フォーマットも不統一です。
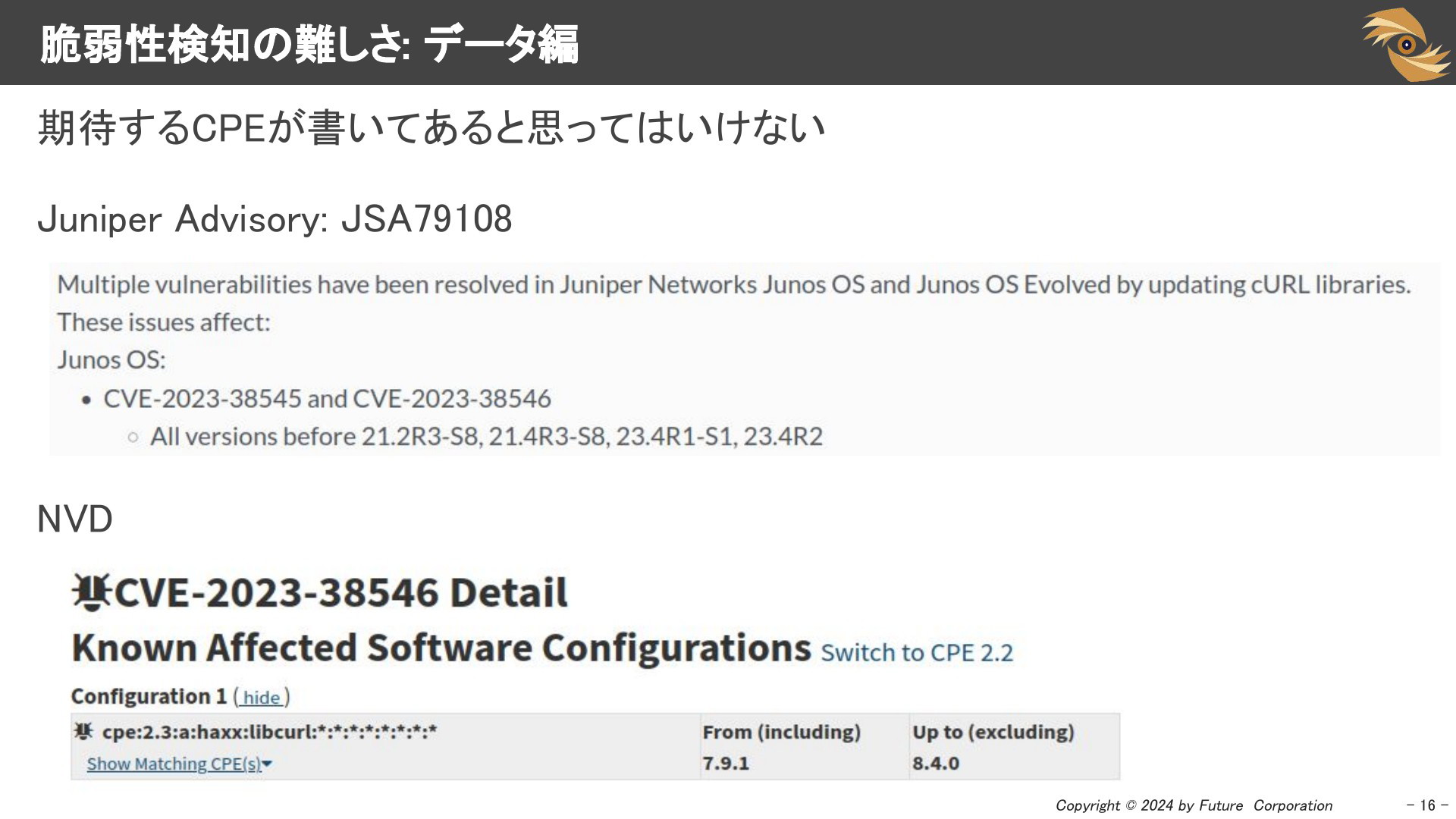
このスライドからは、データ内容に関する課題について紹介します。CPEを利用した脆弱性検知を行う際、NVDの記載とベンダーアドバイザリの内容が異なる場合があります。ベンダーが機械的に処理できるアドバイザリを提供していない場合、ベンダーの情報に基づく検知は難しくなります。
例えば、スライドにあるように、JUNOSではなく、CURLについて記述しなければ、この脆弱性を検知できません。
そのため、未検知だと疑ったとき、ユーザにも脆弱性情報について調査する能力が求められます。
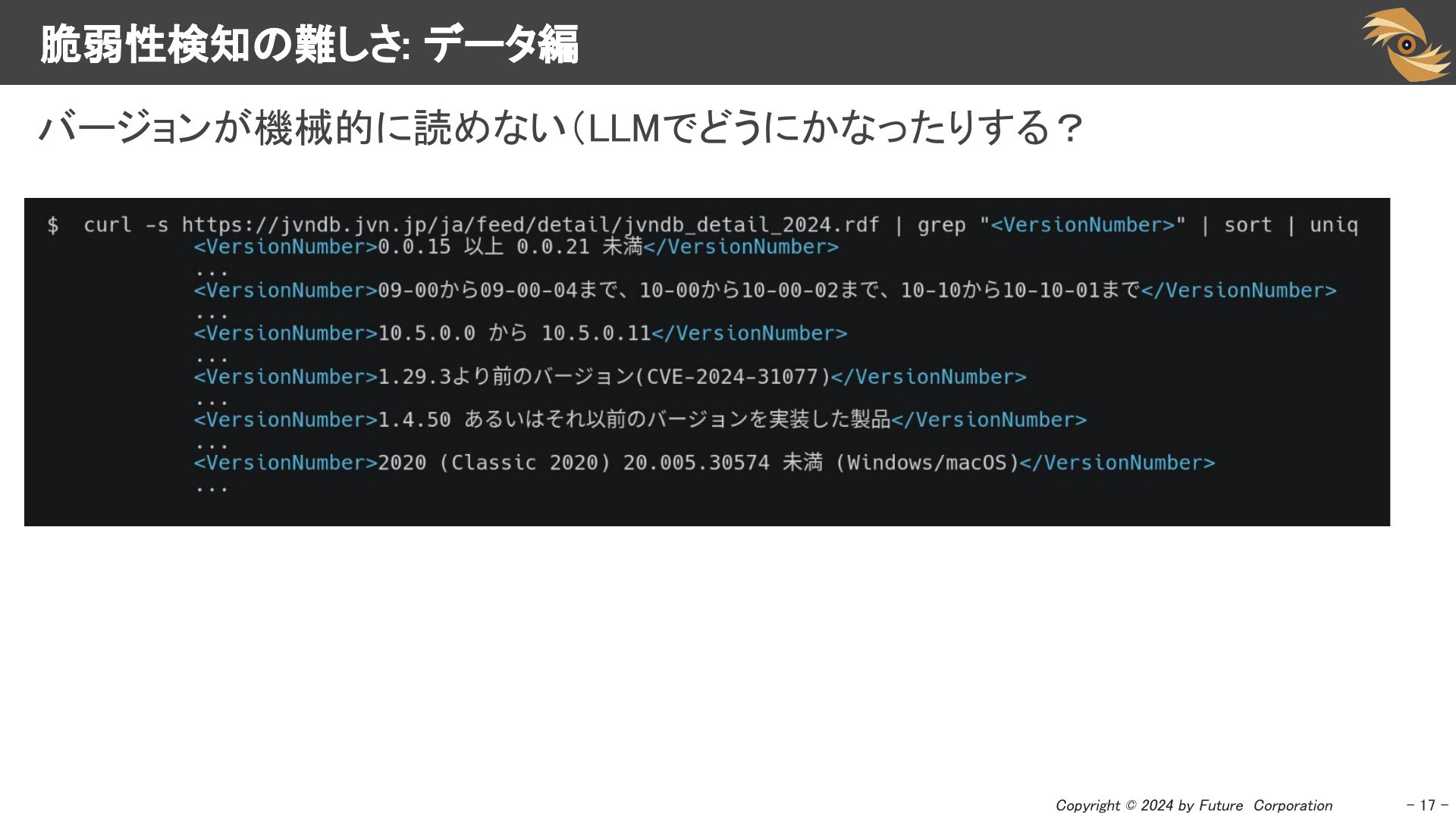
バージョン情報が自然言語で記述されており、例えば「バージョンX以降」や「特定のパッチ適用済み」といった曖昧な表現が使われている場合、機械的に処理しにくいケースもあります。これにより、自動的な比較や検知が難しくなり、手作業での確認が必要になることがあります。例えば、JVNDBでは特定のバージョン文字列が登場し、それを安定して処理するためにはパターン化や大規模言語モデル(LLM)の活用で改善できそうですが、現状では機械処理を想定した定義ではありません。
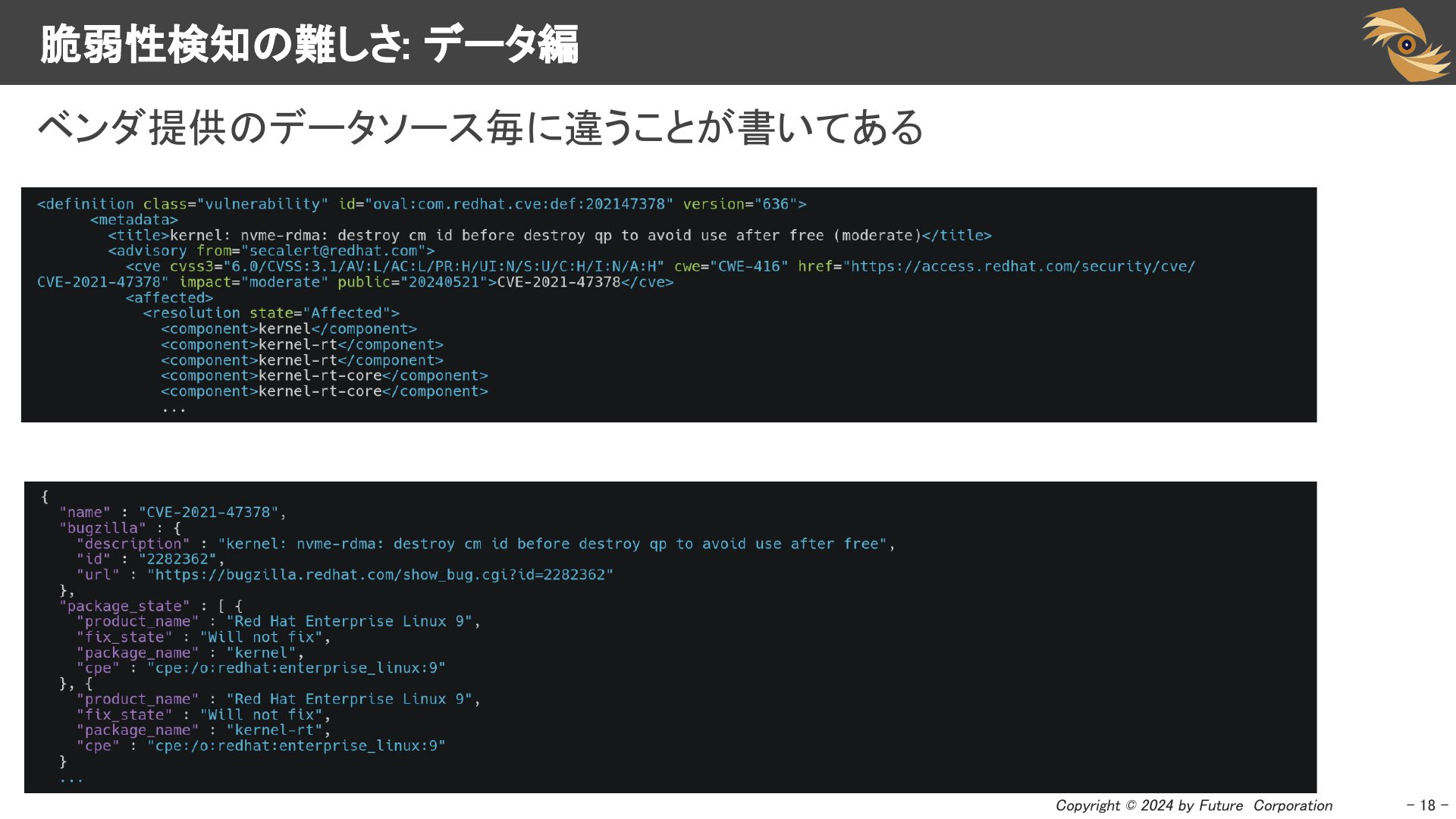
1つのベンダーが複数のデータフォーマットでデータを提供していることがあります。
Red Hatは、CVE API、OVAL、CSAF/CSAF VEX、OSVの4つで脆弱性情報を提供しています(OVALは2024年で終了するみたいですが)。
DebianやUbuntuは、セキュリティトラッカーとOVAL、OSVで提供しています。
異なるデータフォーマットであっても、記述している内容が統一されていればよいのですが、そうではないときがあります。
データフォーマットによっては表現できないものもあるでしょうが、スライド例のようなfix_stateのような部分はしっかりと統一してほしいものです。
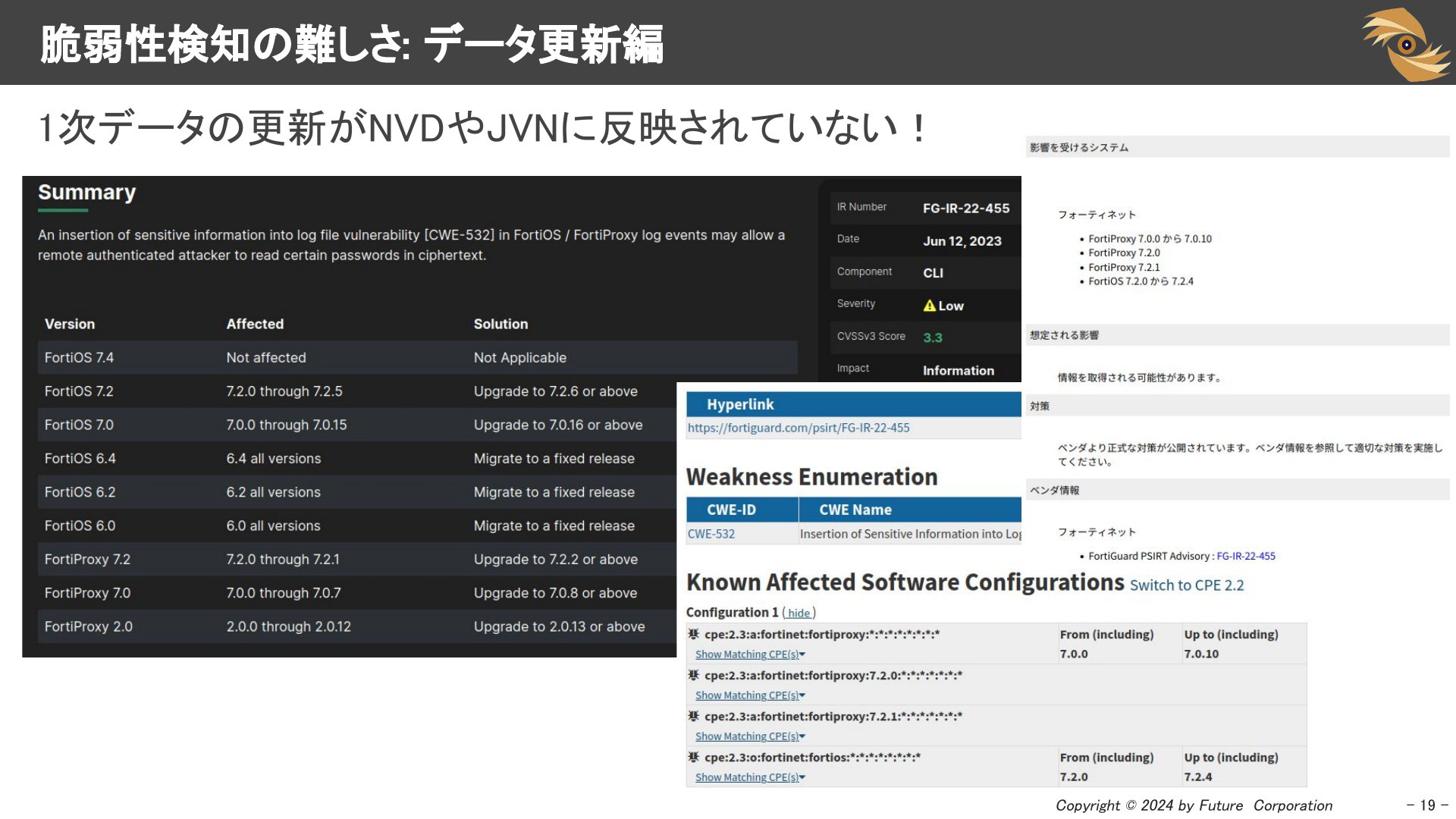
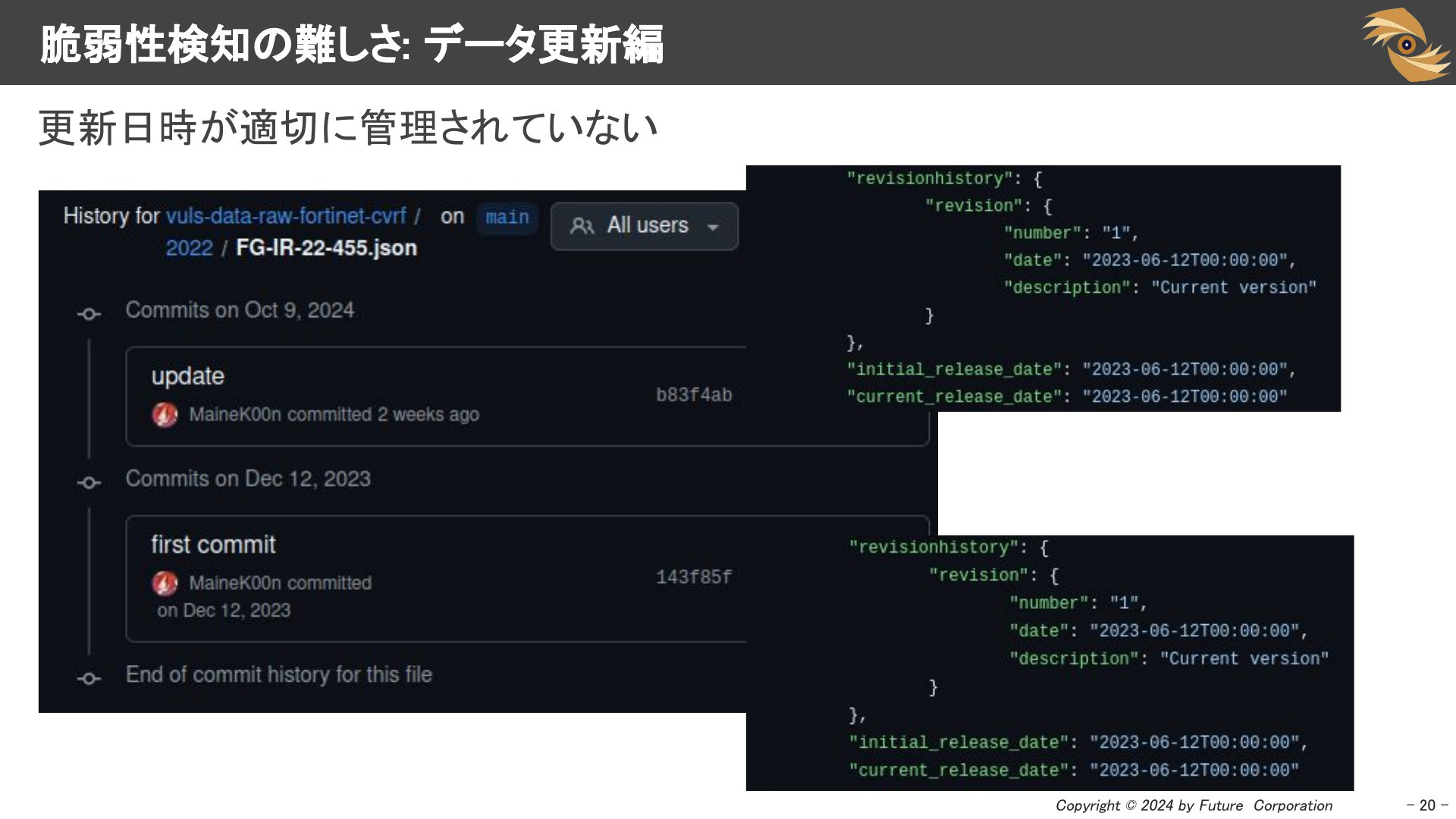
1次データが更新されても、それがNVDやJVNに反映されないケースもあります。今回のケースでは、スライド2枚目にある通り、1次データ側も更新日時を適切に管理していないため、NVDやJVNの担当者が更新に気づくのは困難です。Vulsでは、脆弱性情報の正確性と最新性を確保するために、できる限りベンダーから提供される1次データを収集したいと考えています。
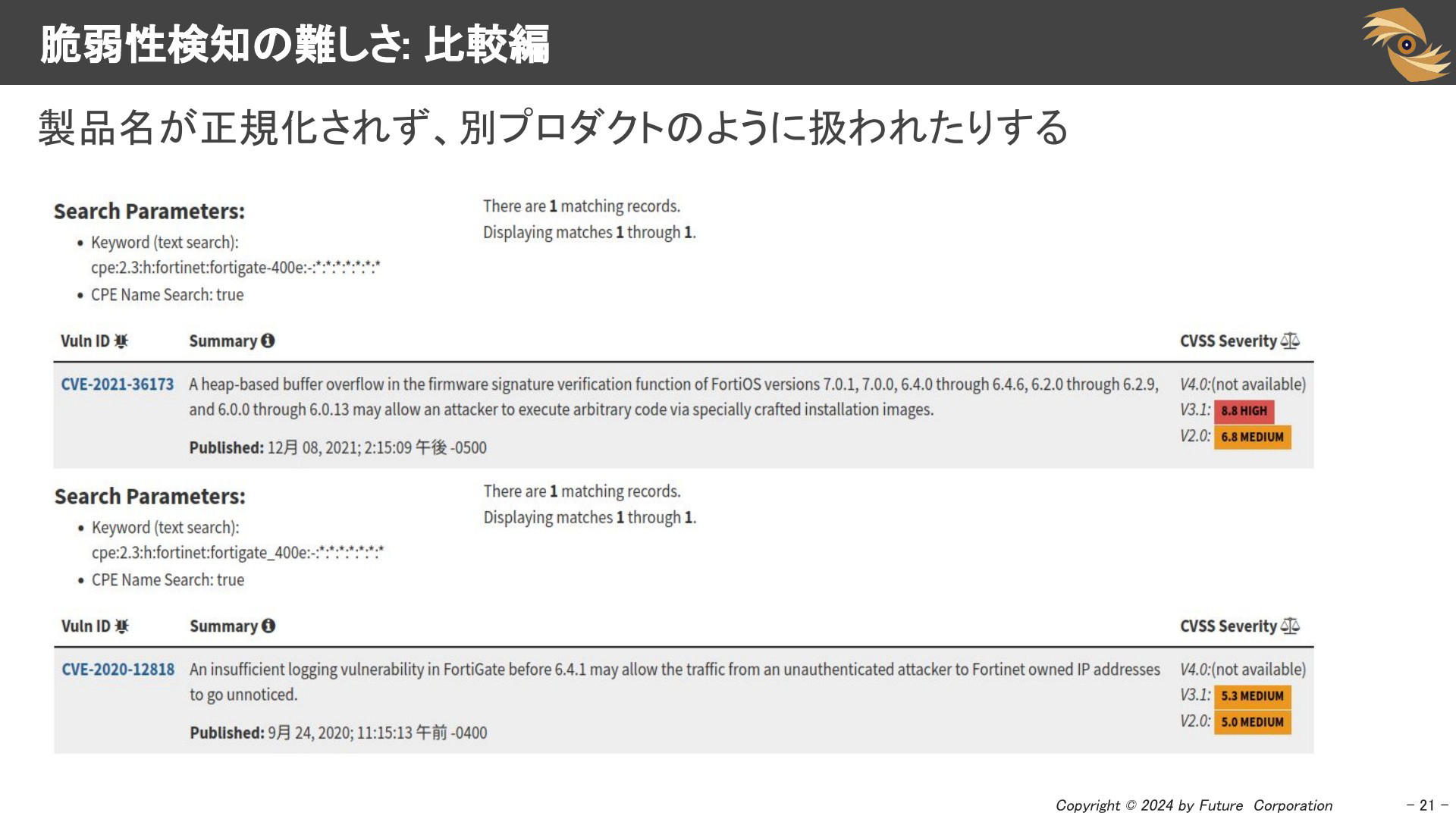
CPEと脆弱性情報を紐付ける際、製品名が正規化されていないことが問題になります。同じ製品でも異なるCPEにそれぞれCVEが紐付けられることがあるため、事前に製品のCPEがどのように表現されているかを調査する必要があります。
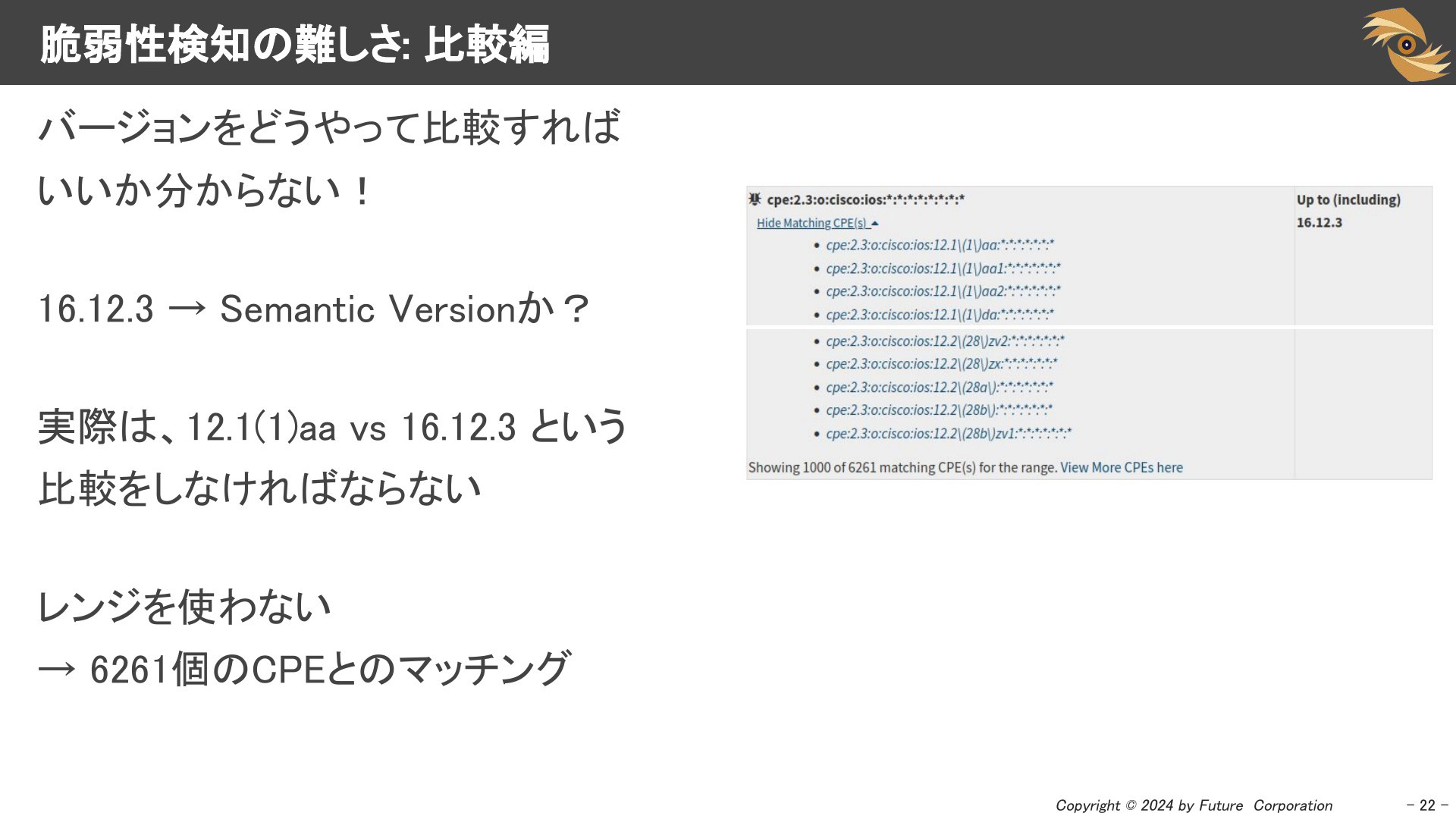
NVDのバージョンレンジにはバージョンタイプ(例: semver)がないため、提供されているバージョンをどう比較すべきか分かりません。幸いにもNVDはバージョンレンジに含まれるCPEを列挙していますが、最大で6261個のCPEとマッチングする必要があります。
ところで、MITRE CVE JSON V5のスキーマには、バージョンタイプを記述するところがあるのですが、customなどが容認されており、少し辛いものがあります。
やはり、バージョンを適切に比較するということはまだまだ難しいと思わせてくれます。

さて、これまでに色々と課題について述べてきました。
まとめると、Vulsのような形での脆弱性検知にとって、脆弱性情報の量と質は検知精度に大きく影響を与えます。
そのため、脆弱性情報の量と質を向上させるために、次の3点に取り組んでもらいたいです。
- 機械的に取得・処理しやすい形で脆弱性情報を提供しよう
- 脆弱性情報をリッチにしてみよう
- もし、脆弱性情報に誤りがあるかも? と思ったら、ベンダーなどに報告してみましょう

最後に、会場ではVuls Nightlyのデモを行いました。
内容は、1次データはすでに公開されているものの、NVDではまだ提供されていないとき、脆弱性DBをカスタムして、検知できるようにするというものでした。
1 | vuls db fetch // 配布されている脆弱性DBを取得する |
3. 膨大な脆弱性と向き合うために



公開される脆弱性は年々増加
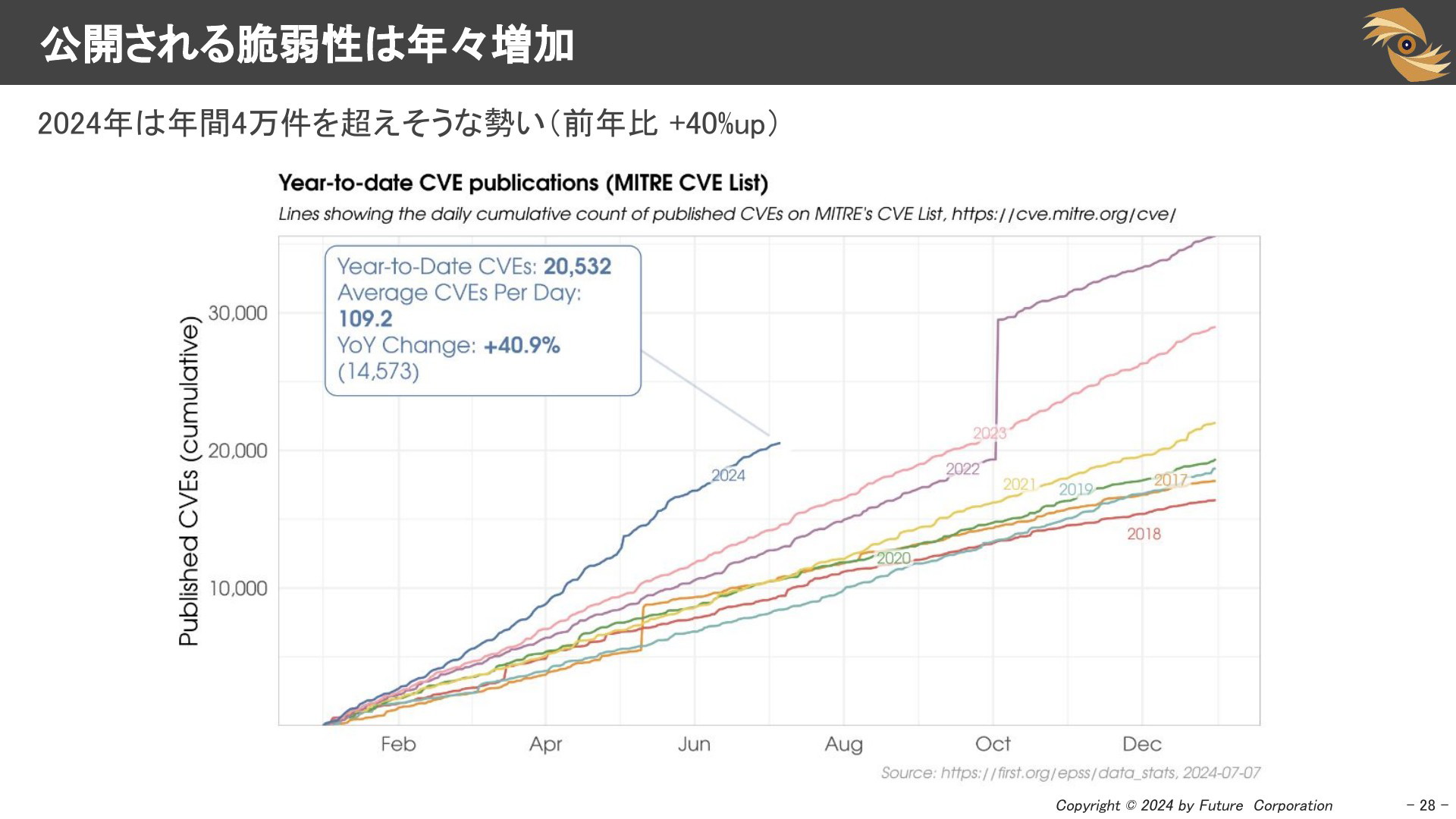
大量の脆弱性が公開され、その数は年々増えています。 2024年は年間で4万件を超えるペースです。
攻撃経路と組織の対応力
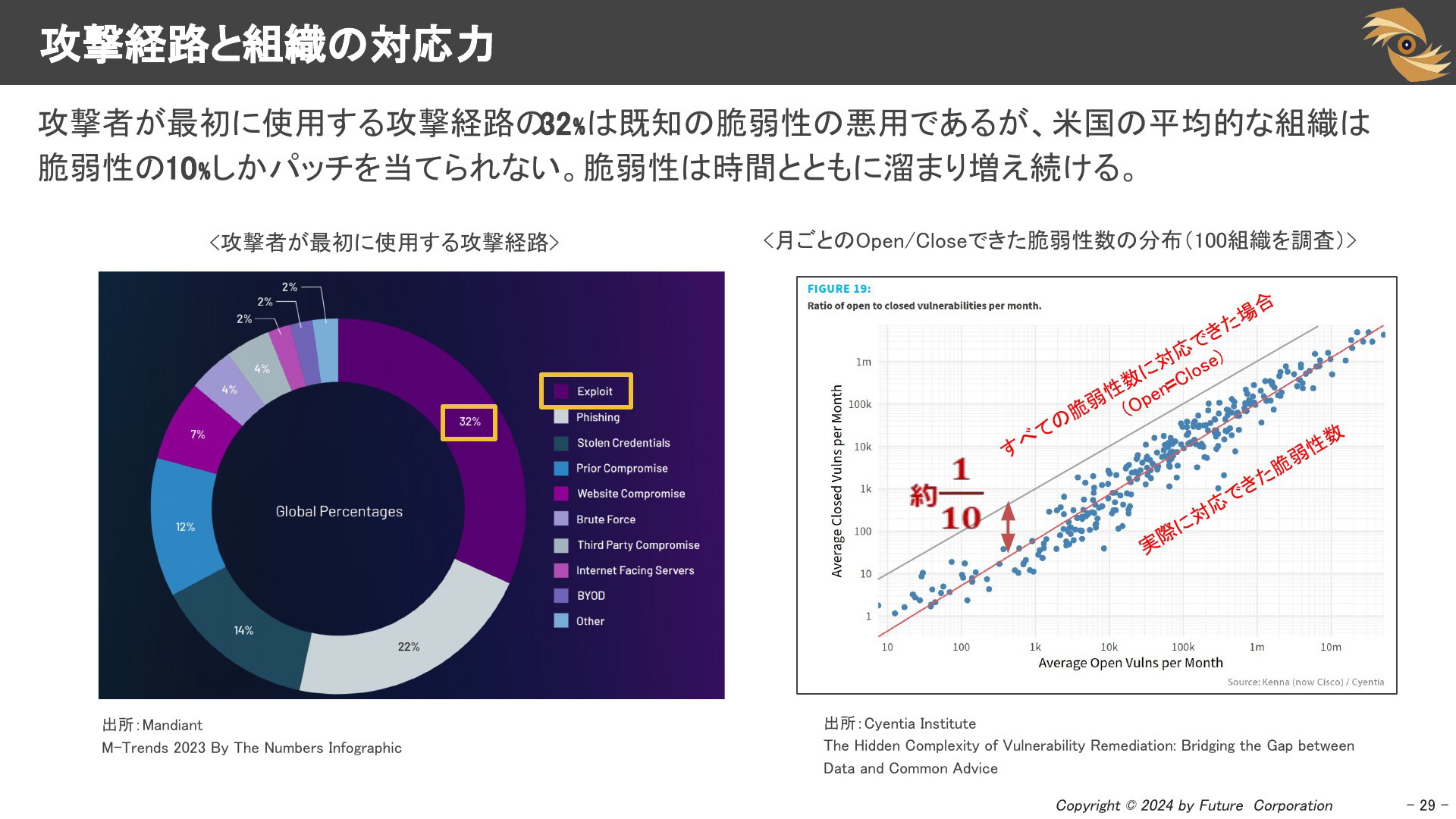
では大量公開される既知の脆弱性を放置するとどうなるでしょうか。攻撃者が最初に使用する攻撃経路の32%は既知の脆弱性の悪用であるというデータが公開されています。一方で組織の脆弱性に対する対応力は十分とは言えません。米国の平均的な組織は脆弱性の10%しかパッチを当てられないというデータが公開されています。米国でも10%です。日本の企業はもっと低いかもしれません。
脆弱性管理のプロセス
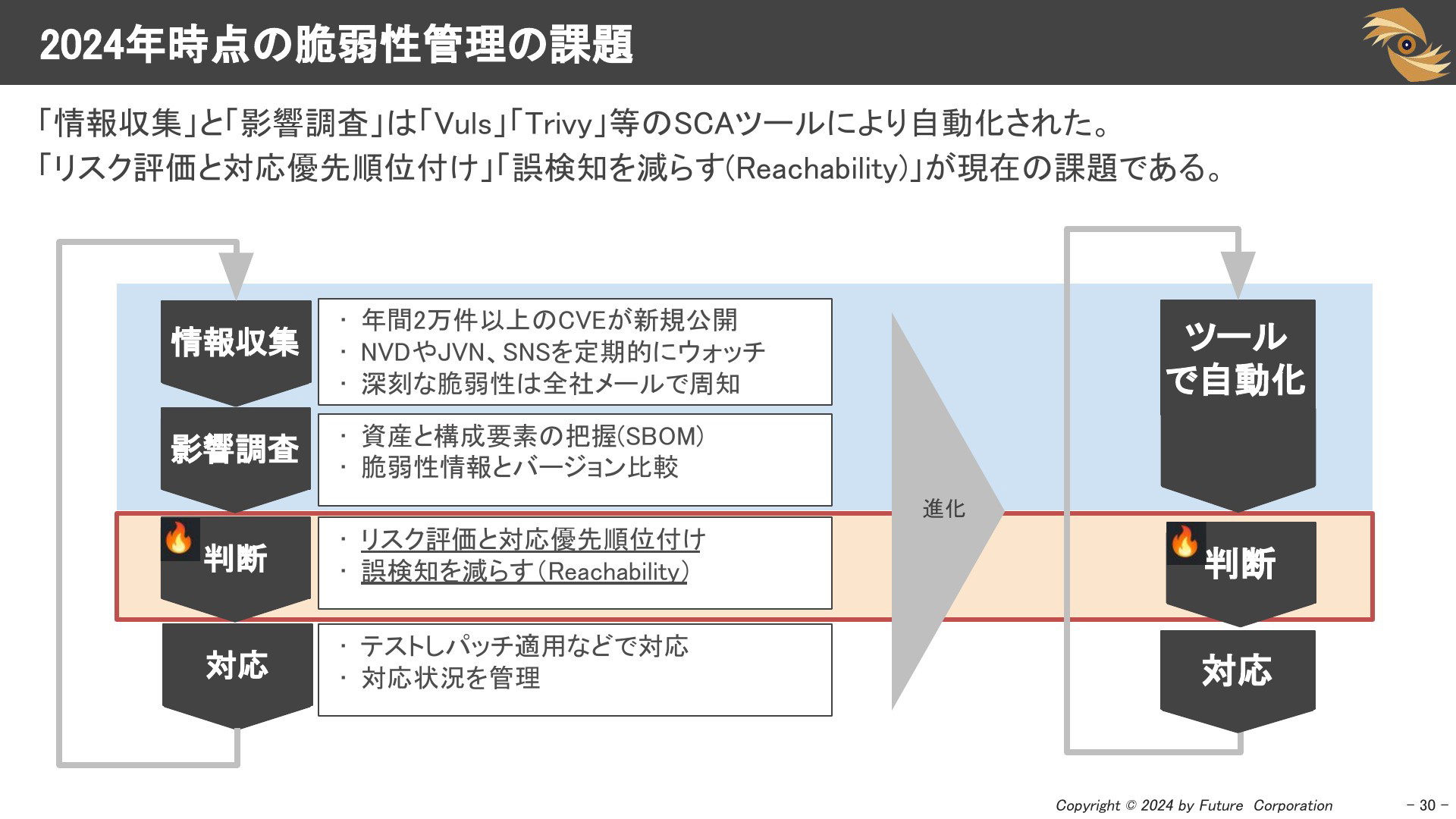
2016年あたりから「Vuls」「Trivyといった」ツールが公開され始めました。これにより「情報収集」と「影響調査」は自動化されていますので、この部分の課題はすでに解決されています。まだ手動でやっている方はツールを使いましょう。
2024年現在の脆弱性管理の課題は、検知後の「判断」の部分であり、以下の2点が課題です
- リスク評価と優先順位付けによる、対応可能な数までの絞り込み
- ツールが検知した誤検知な脆弱性を減らす

まずは、1. リスクを評価して対応優先順位付けするから詳細を見ていきます。
基本:CVSSスコアとは
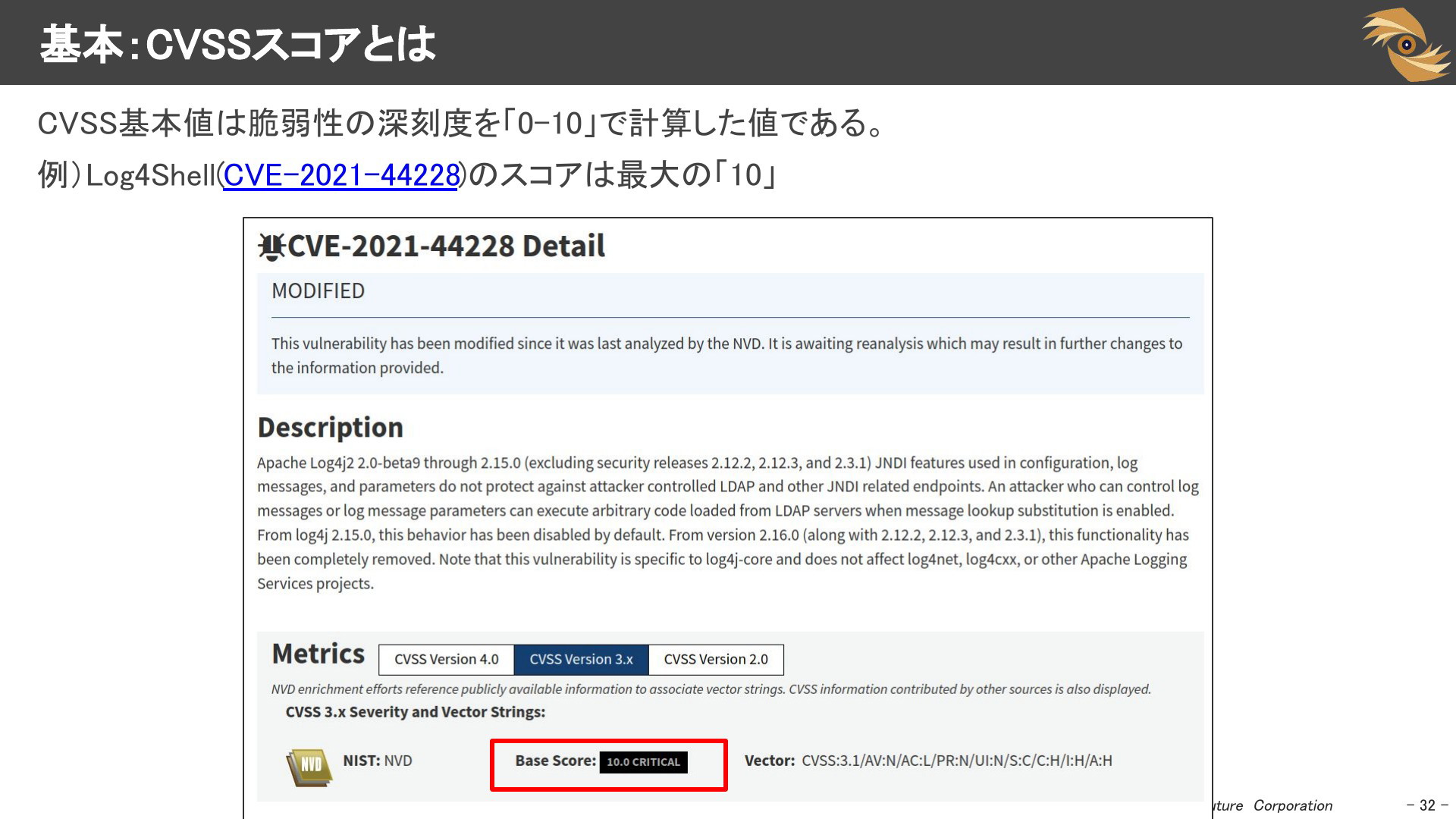
ご存じの通り、脆弱性にはCVEというIDがつけられます。CVEはCVSSと呼ばれる脆弱性の深刻度を「0-10」で計算した値がセットで公開されます。Log4Shell(CVE-2021-44228)のスコアは最大の「10」がつけられています。また、Vectorには、「NWからの攻撃可能か」「複雑化」「権限が必要か」「機密性・完全性・可用性」のどれに影響するかといったようなそのCVEの技術的な特徴が書かれています。
CVSSスコアでの絞り込みについて
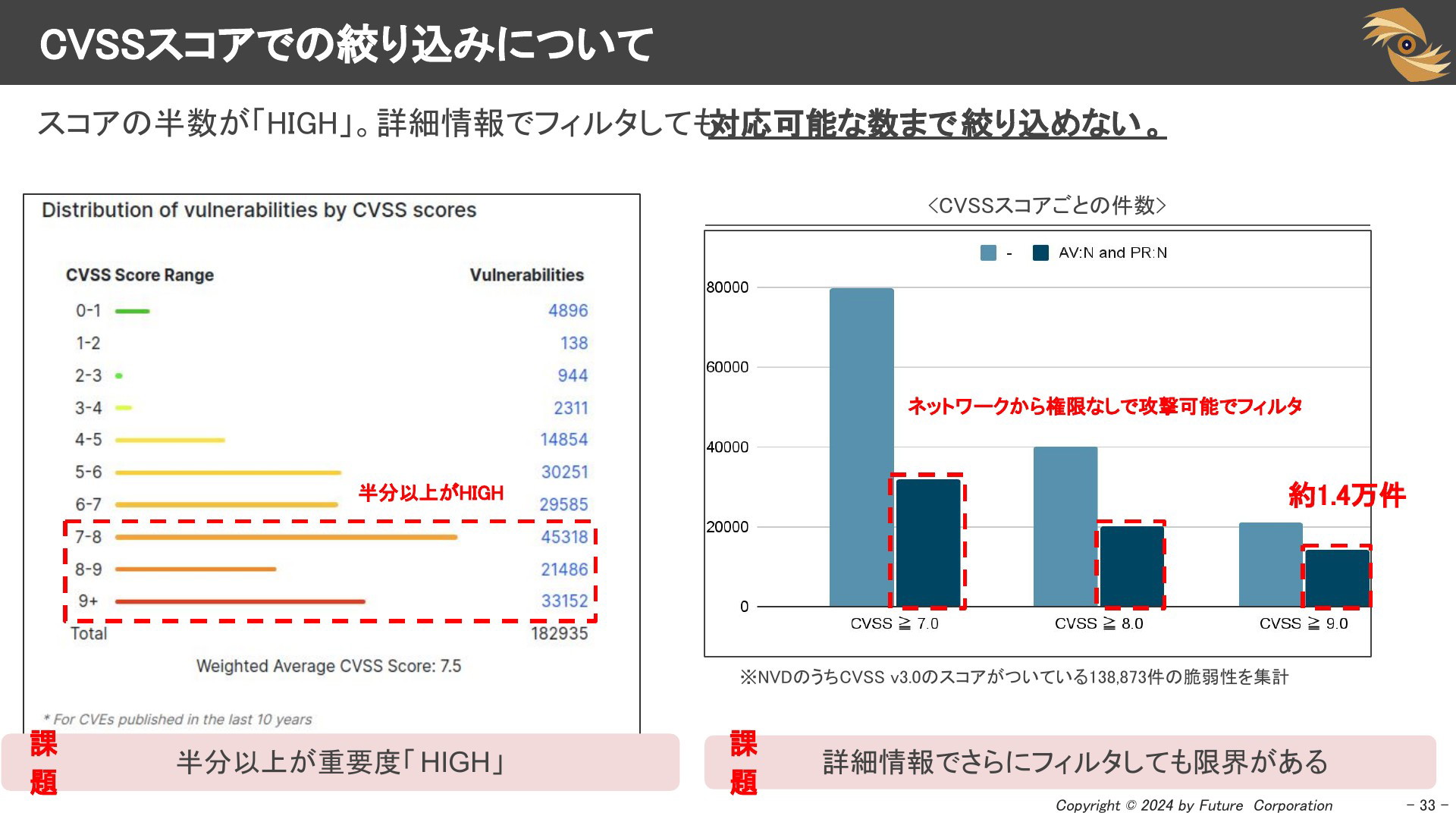
優先度付けのためにはCVSSスコアでフィルタすれば良いと考えるかもしれませんが、公開されている全てのCVEのスコアの半数は「HIGH」がつけられます。脆弱性の半分が「重要度HIGH」です。CVSSスコアだけでは絞り込めないのなら、CVSS Vectorも使って絞るのはどうでしょう。CVSSスコアが「9以上かつ、インターネット越しに、権限なしで攻撃可能」なものを絞り込んだところ「1.4万件」もヒットしてしまいます。
このように詳細情報でフィルタしても対応可能な数まで絞り込めないのが実情です。
CVSSスコアと武器化の関係
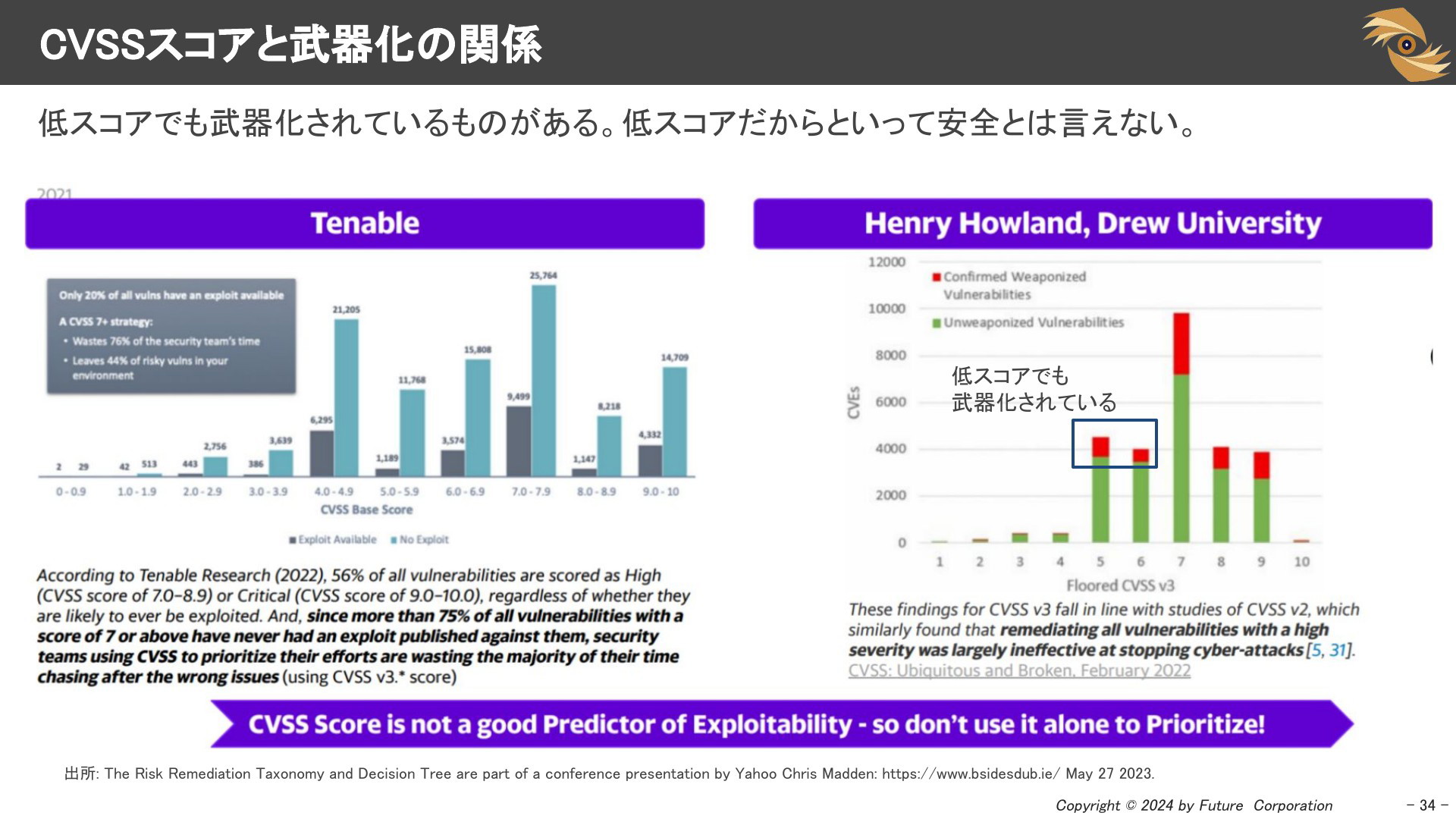
また、CVSSスコアが高いものだけが実際の攻撃に使われているわけではありません。CVSSスコアが低いものにも攻撃コードがあり、安全とは言えません。以下のデータを見ると、CVSSスコアが「4.0-6.0」な「Medium」な脆弱性にも悪用されているものがあります。また、「7」以上の脆弱性でも実際に武器化されているものは少数であることがわかります。
つまり、CVSSスコアだけで判断するととても効率が悪い対応になってしまうということです。
リスクとは
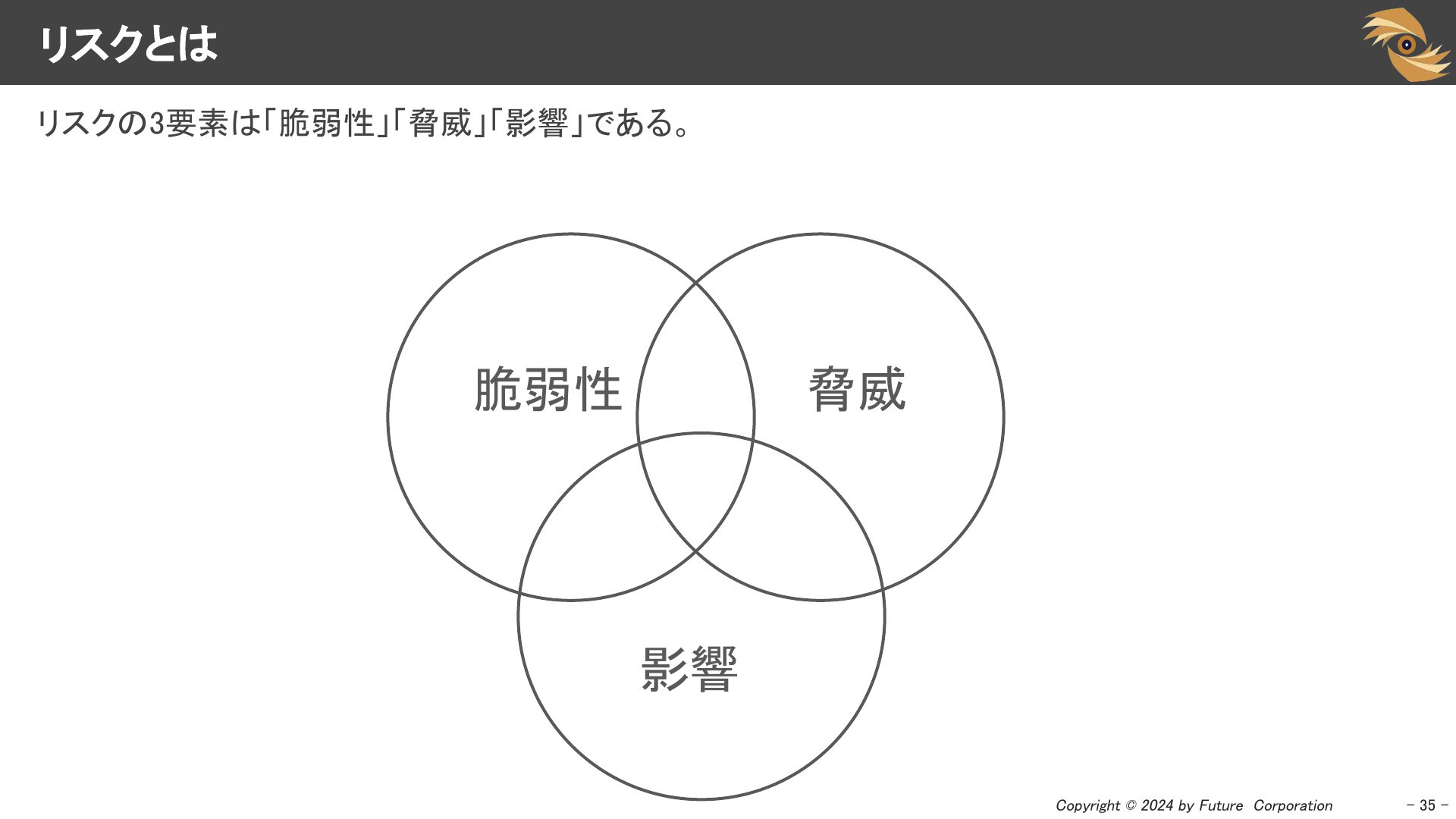
「リスク」について一度おさらいしましょう。リスクの要素は「脆弱性」「脅威」「影響」です。どんなに深刻な脆弱性でも、実際に悪用されていないとリスクはゼロです。また、そのソフトウェアは利用していない場合や、ビジネス面で重要ではないなどの理由で自社に影響がなければリスクは低いということになります。
脅威情報
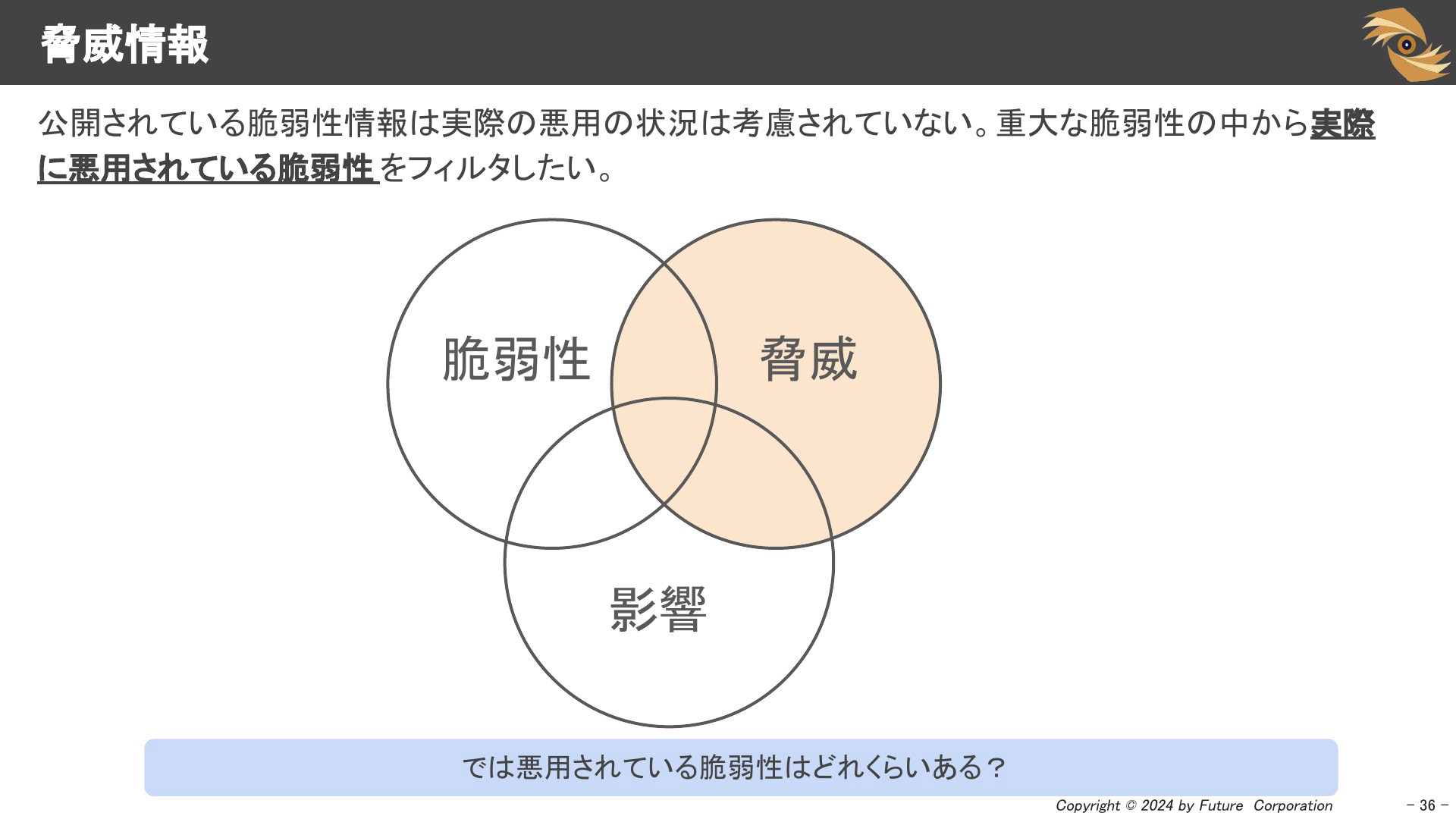
NVD等で公開されている脆弱性情報のCVSSスコアは実際の悪用の常用は考慮されていません。
重大とされる脆弱性の中から、「実際に悪用されている脆弱性」をフィルタして絞り込みをすればよさそうです。
では悪用されている脆弱性はどれくらいあるのでしょうか。
実際に攻撃に使われる脆弱性とは

それでは、実際に攻撃に使われている脆弱性はどれくらいあるのでしょうか。以下のデータを見ると、実際に攻撃に使われている脆弱性は「2-4%未満程度」だそうです。実際に攻撃に使われているものは最優先に対応する必要があります。CVSSスコアではこの2-4%の脆弱性を絞り込むことはできません。
実際に攻撃に使われる脆弱性の割合とは
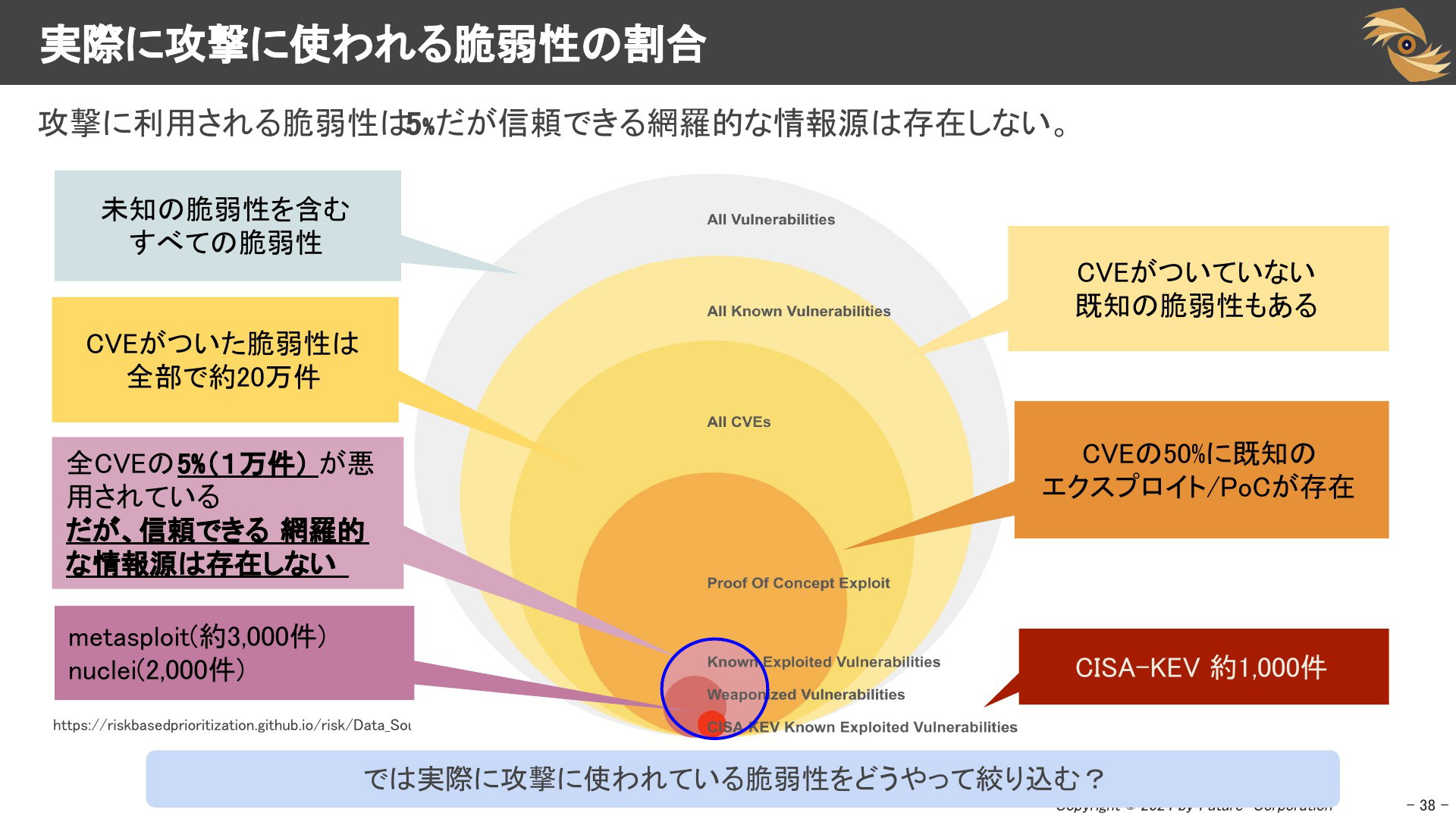
図で示している青枠で囲われている部分が実際に攻撃に使われいている「5%」の脆弱性です。
この5%の脆弱性は信頼できる情報ソースから網羅性のあるリストとして、提供されて「いません」。
では、この青枠をどうやって絞り込んでいったらよいでしょうか。
無料で公開されている脅威情報の例
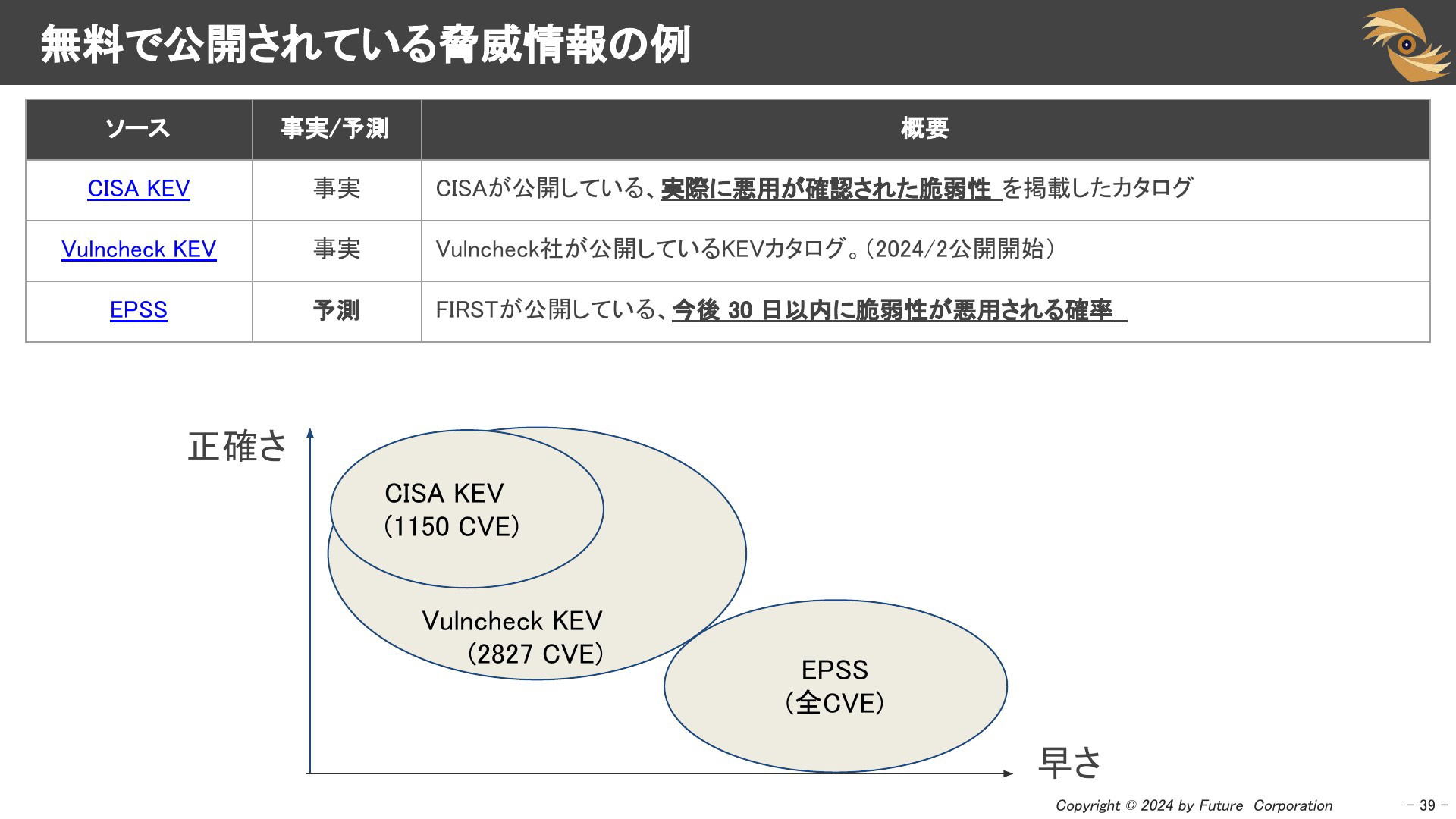
1つ目は「CISA KEV(Known Exploited Vulnerabilities Catalog)」です。CISA-KEVは、CISA(米国サイバーセキュリティ・インフラセキュリティ庁)が公開している実際に悪用が確認された脆弱性のリストです。CISA-KEVを参照することで、多数ある脆弱性のうち、特に悪用されるリスクが高く、かつ明確な対策が公開されている脆弱性の見逃しを防ぐことができます。
2つ目は「Vulncheck KEV」です。Vulncheck社が無償で公開しているKEVです。CISA-KEVよりも80%多く、27日早く掲載されるとのことです。APIが公開されているのでスクリプトから取ってきてツールに組み込むこともできます。
3つ目はFIRSTが公開している「EPSS」(Exploit Prediction Scoring System)です。今後30日以内に脆弱性が悪用される蓋然性を一定の計算式によって算出したものです。
下の図は「正確さ」「掲載の早さ」について3つのデータソースの特徴を図示したものです。
一番信頼性の高いものは、CISA-KEVです。2024/8/20現在1150個くらいが掲載されています。米国政府系システムにおいてこのリストに掲載されたものは、定められた期限までに対応必須となるので、ここに載せるということは実際の対応コストがかかります。CISAとしては明確な悪用実績の証拠の確認作業が必要となるため掲載の早さ面からは遅いという情報ソースです。詳細はFIRSTCON2024@福岡の CISAの発表「A Deep Dive into KEV」をご覧ください。
2番目に信頼性の高いものは、「Vulncheck-KEV」です。2024/8/20時点で2827個のCVEが掲載されています。CISA-KEVよりも掲載速度が早いという特徴があります。また、CISA-KEVは悪用についてのデータソースが公開されていませんが、Vulncheck-KEVにはURLが記載されていますので確認できます。
3番目はEPSSです。KEVは悪用の事実をもとに作成されたリストですが、EPSSは「予測」している点が異なります。未来を予測するの正確性は下がります。全てのCVEのスコアが公開されています。
リスクを考慮した脆弱性管理とは
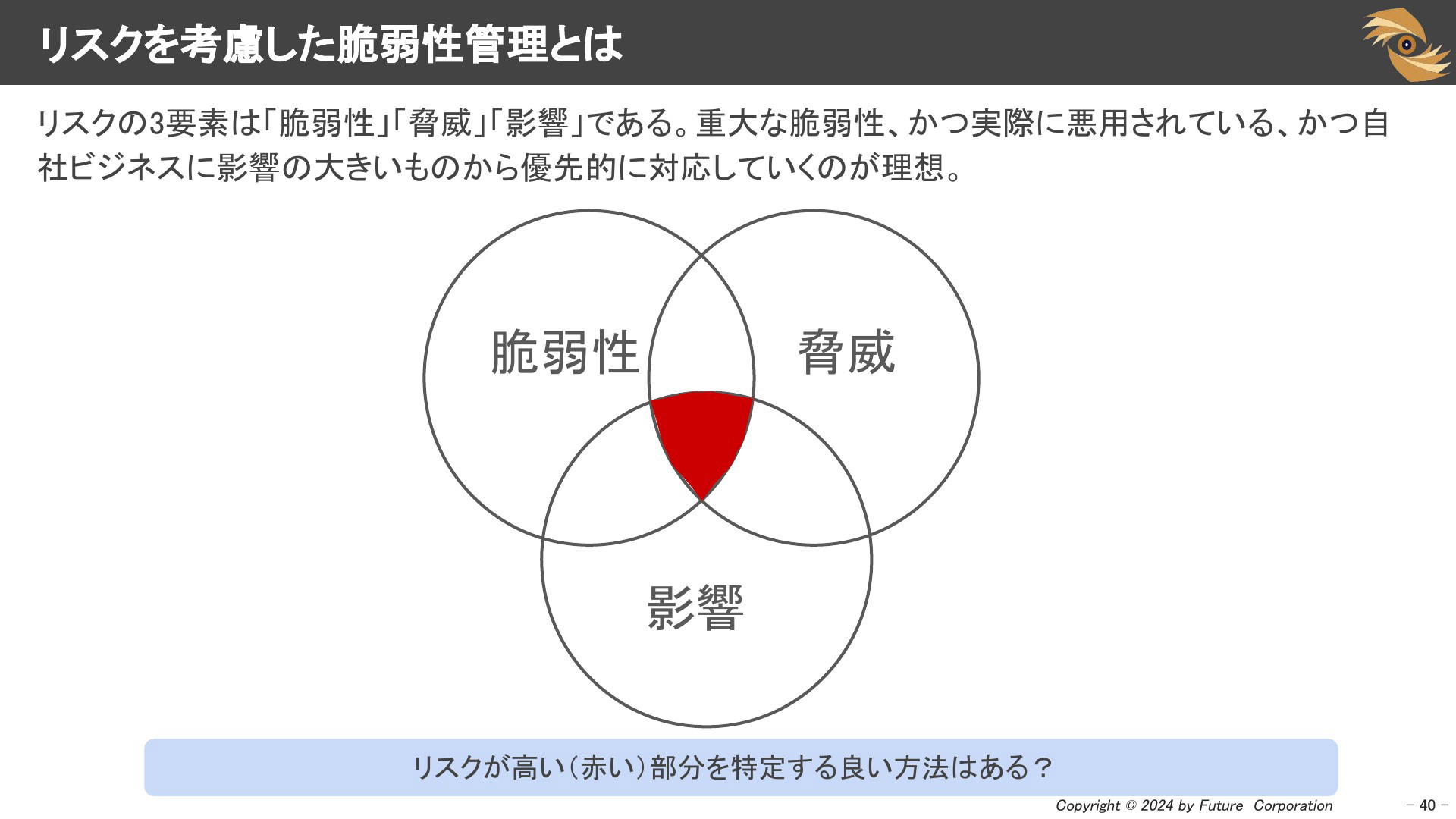
さて「リスク」についてもう一度おさらいしましょう。リスクの要素は「脆弱性」「脅威」「影響」でした。脆弱性管理では組織の対応力が限られるため、自組織に影響のある高リスクな脆弱性から順番に対応する必要があります。つまり重大な脆弱性、かつ実際に悪用されている、かつビジネスに影響の大きいものから優先的に対応していくのが理想です。この高リスクな脆弱性を具体的にどうやって絞り込めば良いでしょうか。それを実現するために使えるフレームワークが「SSVC」です。
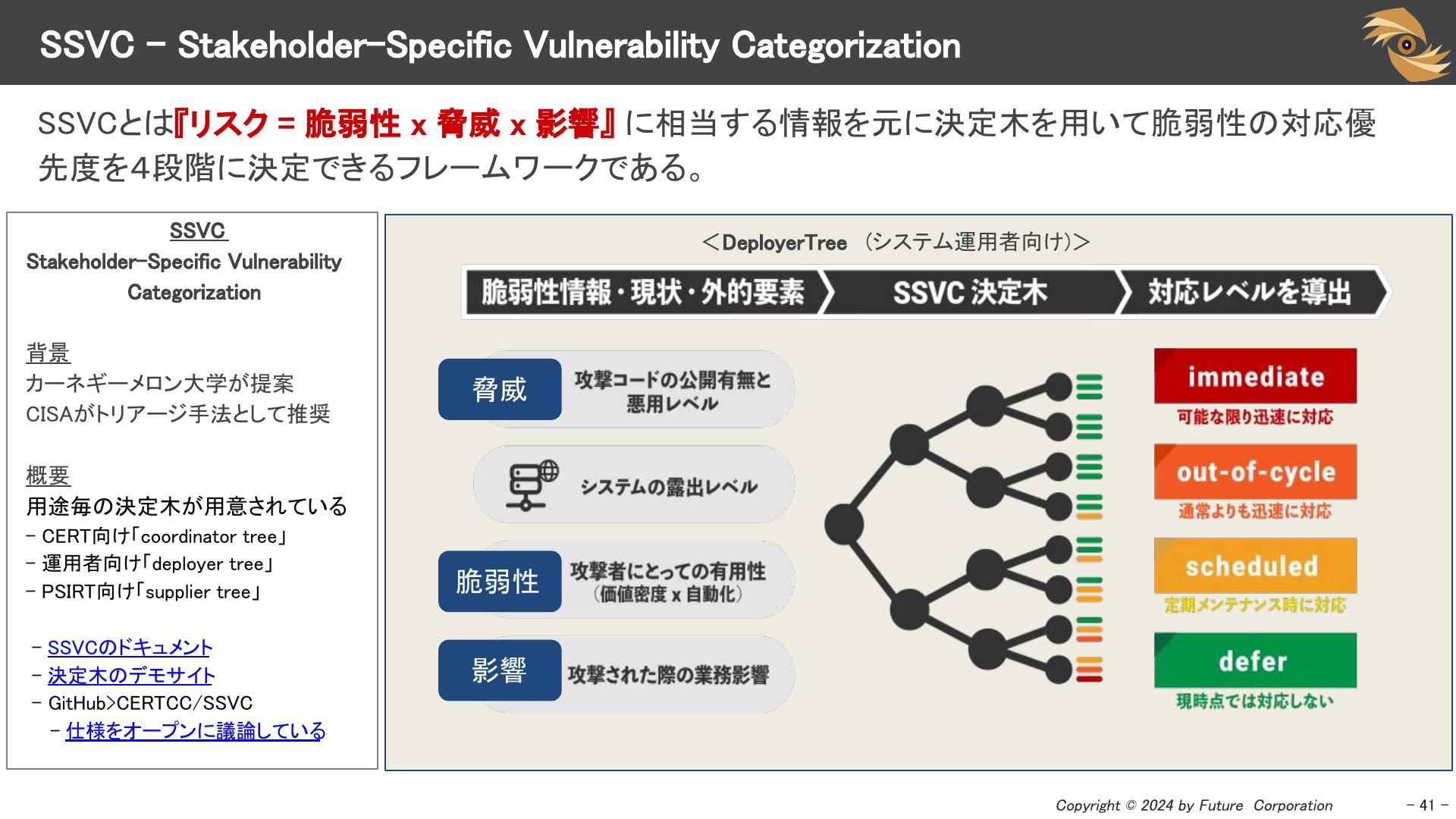
SSVC - Stakeholder-Specific Vulnerability Categorization

SSVC - Stakeholder-Specific Vulnerability Categorization
SSVC (Stakeholder-Specific Vulnerability Categorization)は、カーネギーメロン大学が開発し、米国のCISA(Cybersecurity and Infrastructure Security Agency)でも採用されているフレームワークです。脆弱性に関するリスクを「脆弱性」「脅威」「影響」の3つの要素に基づいて評価し、それに応じた優先度を決定します。
2024年7月現在、以下の役割ごとに異なる決定木が用意されており、利用者の立場に応じて利用する決定木を使い分けます。
- CERTや企業のリサーチャー向けの「Coordinator Tree」
- システム運用者向けの「Deployer Tree」
- パッチ提供者向けの「Supplier Tree」
3つの決定木については「SSVC-calc」で詳細を確認できます。この決定木を「あみだくじ」のように辿っていけば、検知した脆弱性の対応優先度が4段階で決定できるイメージです。

SSVC-calcの実際の使い方はVulsまつり#10のYouTubeの動画がわかりやすいと思います(18:30〜)
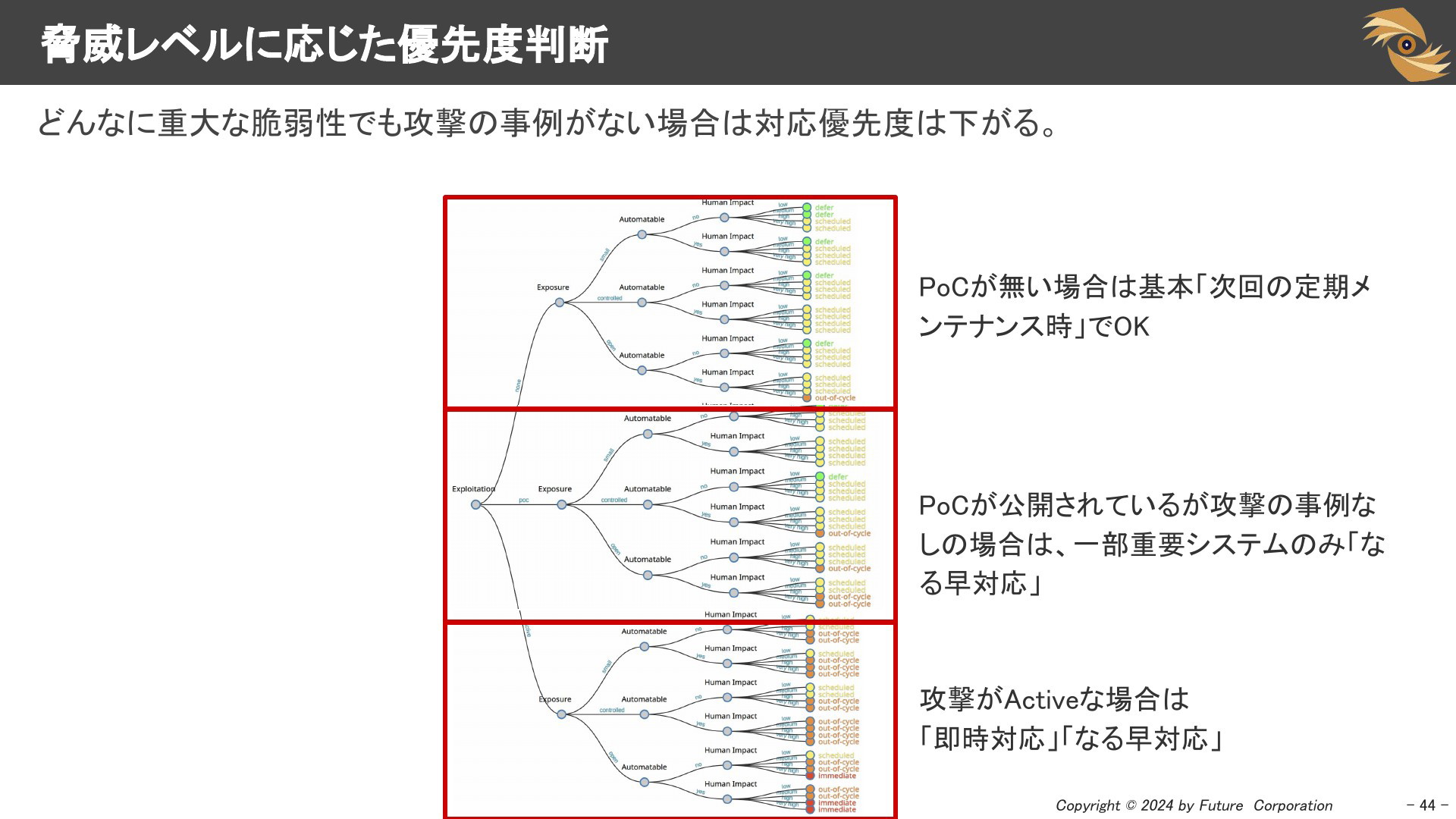
脅威レベルに応じた優先度判断
たとえば、CVSSスコアが10のような重大な脆弱性でも攻撃の事例がない場合は脅威のレベルは下がりますので対応優先度は下がります。
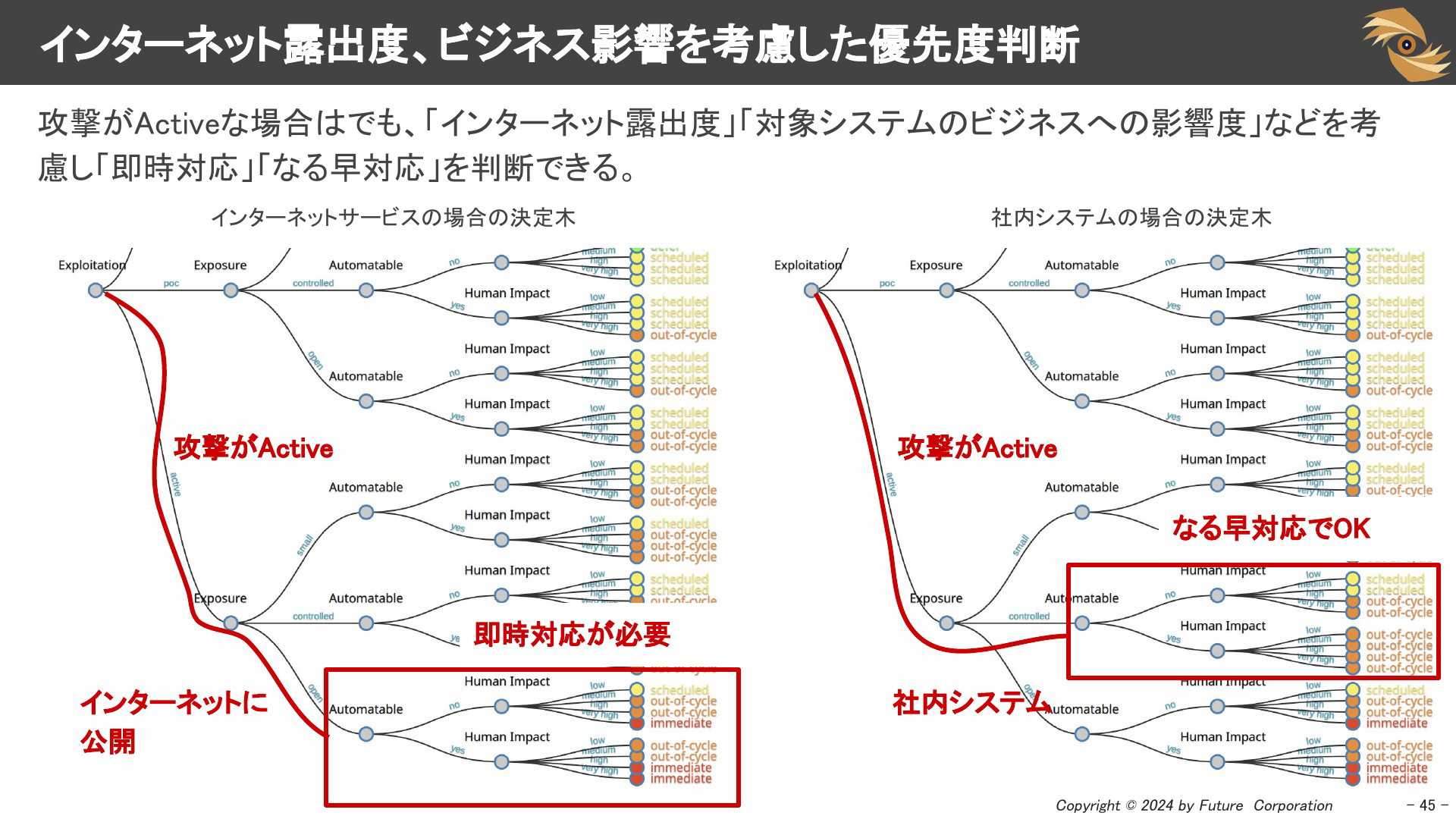
インターネット露出度、ビジネス影響を考慮した優先度判断
攻撃がActiveな場合は、「インターネット露出度」「対象システムのビジネスへの影響度」などを考慮して判断されます。インターネットに公開されているシステムの場合は「即時対応」、社内システムの場合は「なる早対応」と判断されます。CISAのKEV-catalogに掲載された場合でも全てが即時対応必須であるという判断にはなりません。
SSVC Deployer Treeで実際に実験してみた
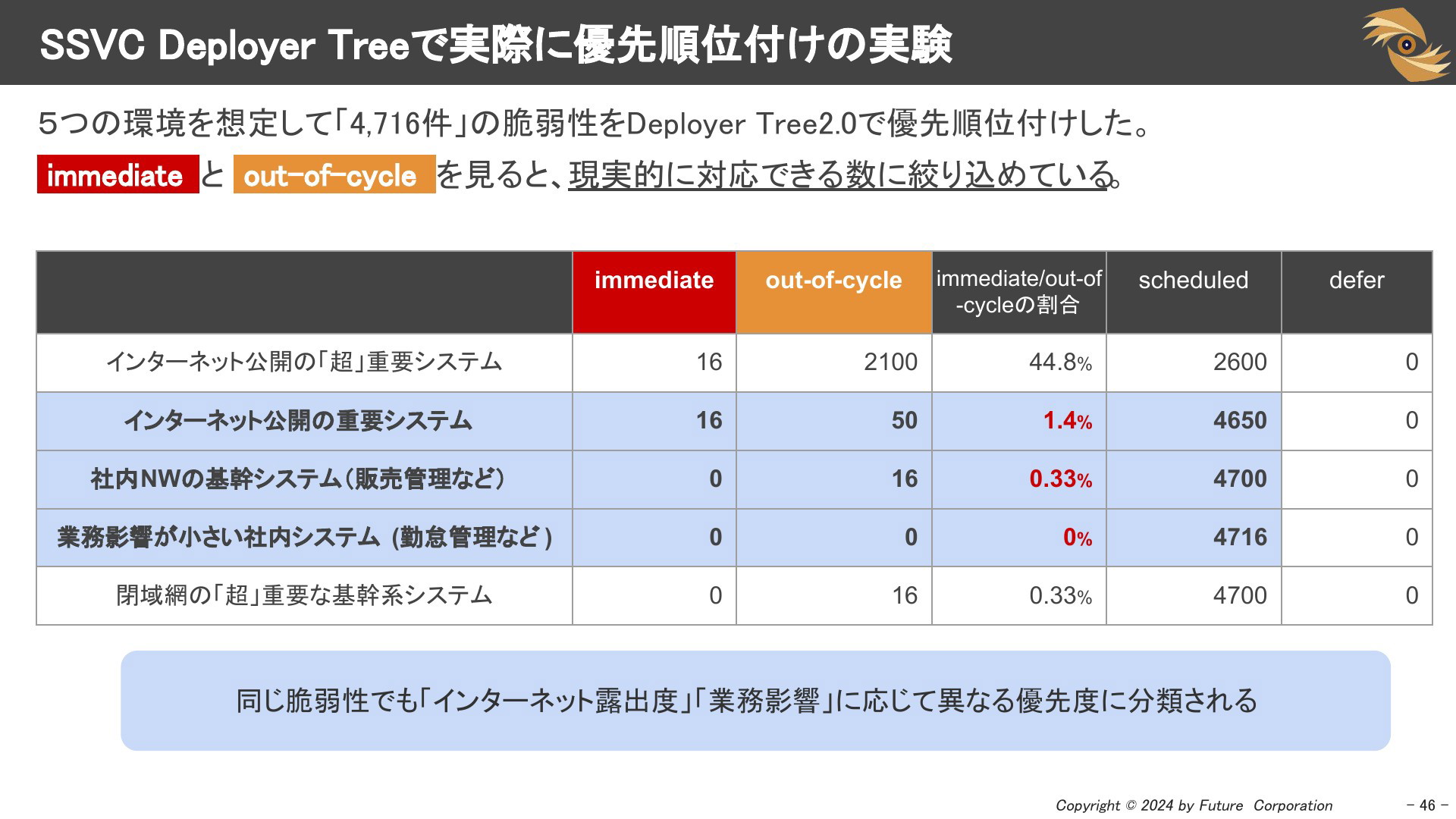
5つの環境を想定して、「4,716件」の脆弱性をSSVCで分類してみました。インターネットに公開された重要システムを見ると、緊急対応「Immediate」となる早対応「Out-of-cycle」が「1.4%」まで絞り込めました。また、インターネットに公開されていない社内システムはさらに絞れます。「緊急」「重大」な脆弱性に対して必要以上に即時対応をする事態は解消され、現実的に対応できる数に絞り込めています。
SSVCのまとめ
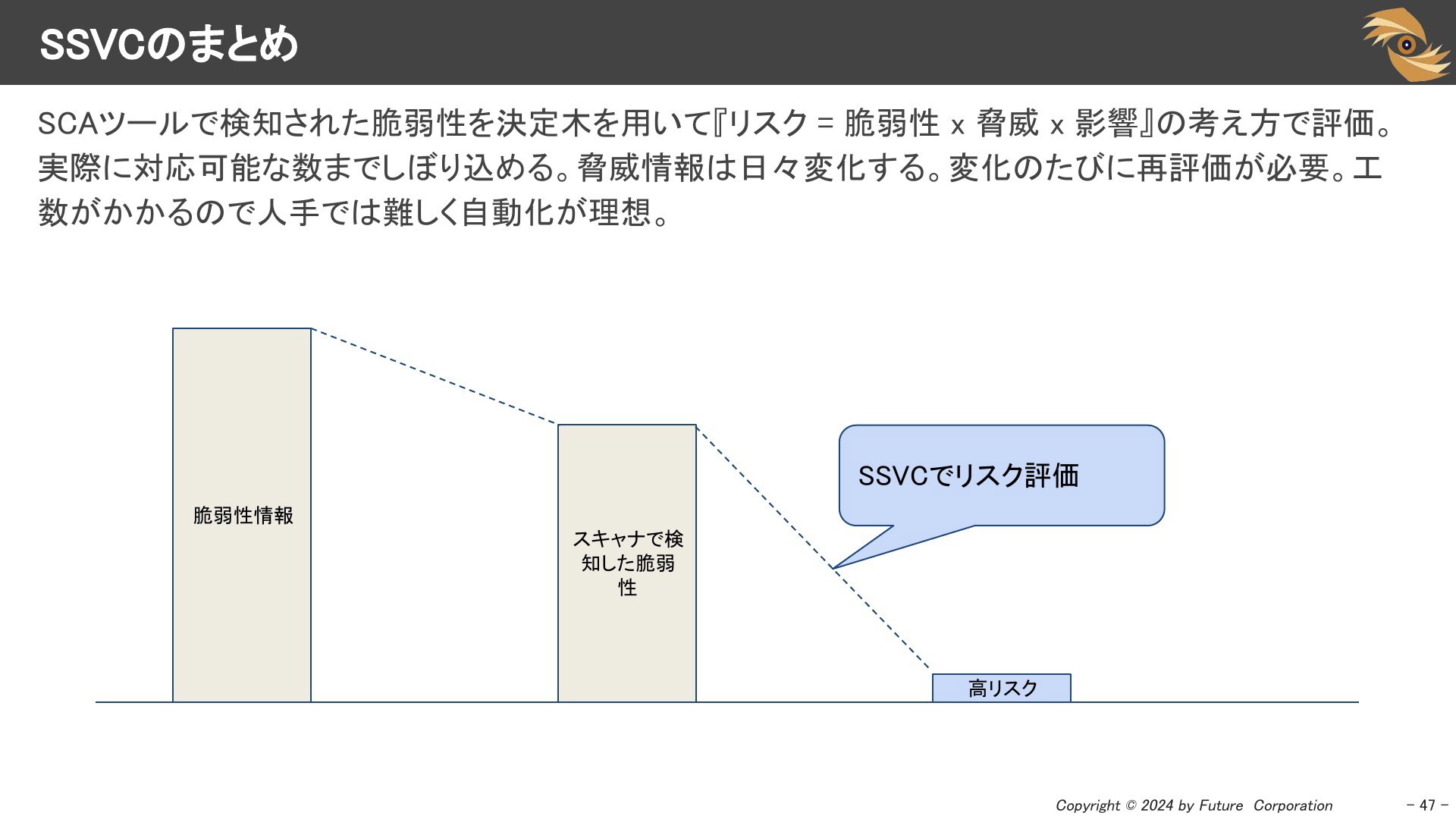
SCAツール等で検知された脆弱性をSSVCを用いて優先度判断する考え方を詳細に説明しました。ただこの優先度判断を人力でやると工数がかかりますので紹介した情報ソースや、SSVC対応の有償サービスなどを用いて自動化するのが理想です。
2. 誤検知・ノイズを減らす Reachability

次に、誤検知、ノイズを減らす話に入っていきます。
誤検知・ノイズを減らす Reachability
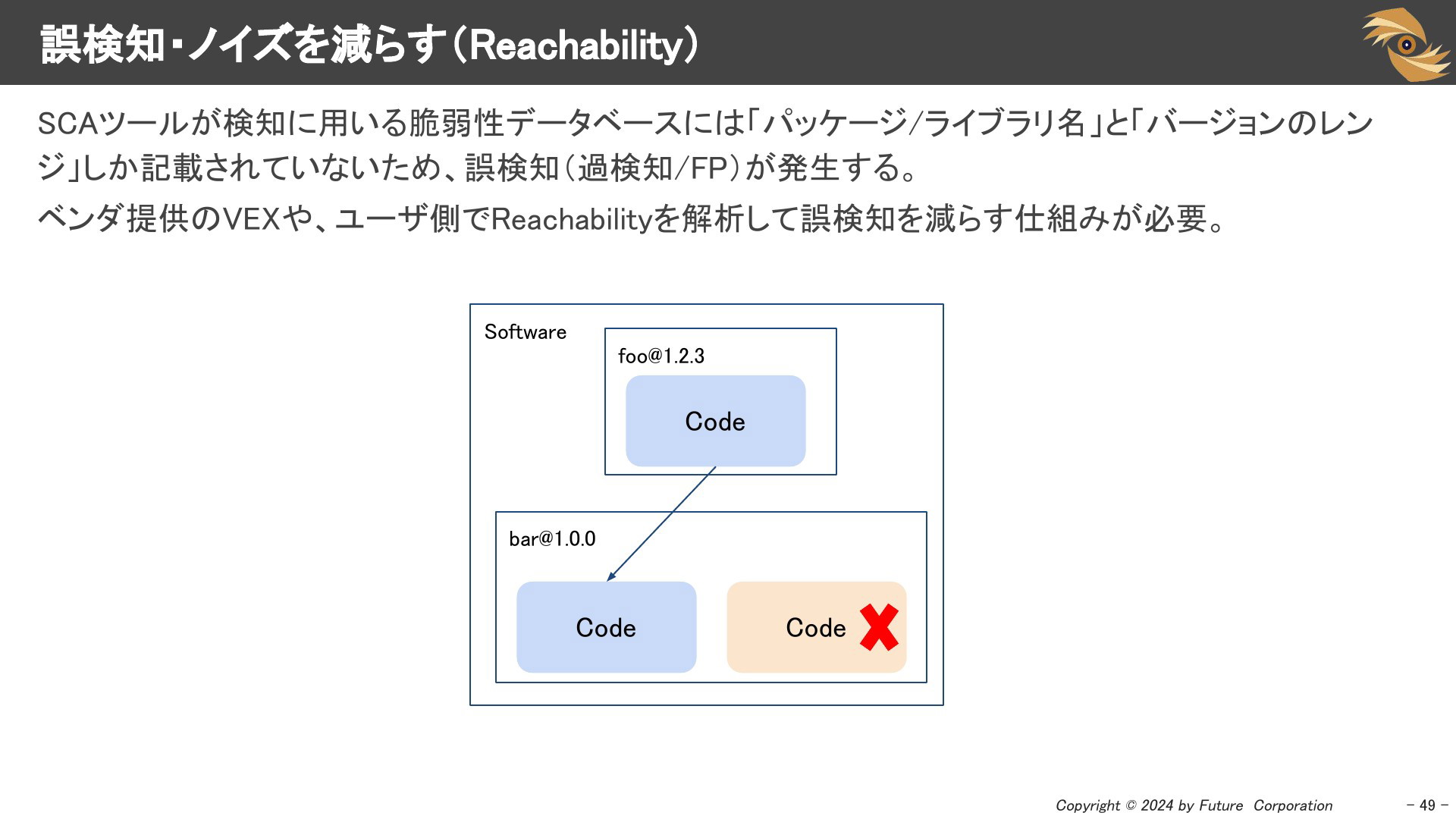
SCAツールが検知に用いる脆弱性データベースには「パッケージ/ライブラリ名」と「バージョンのレンジ」しか記載されていないため、誤検知(過検知/FP)が発生します。ベンダー提供のVEXや、ユーザ側でReachabilityを解析して誤検知を減らす仕組みが検討されています。
誤検知・ノイズを減らす(Reachability)
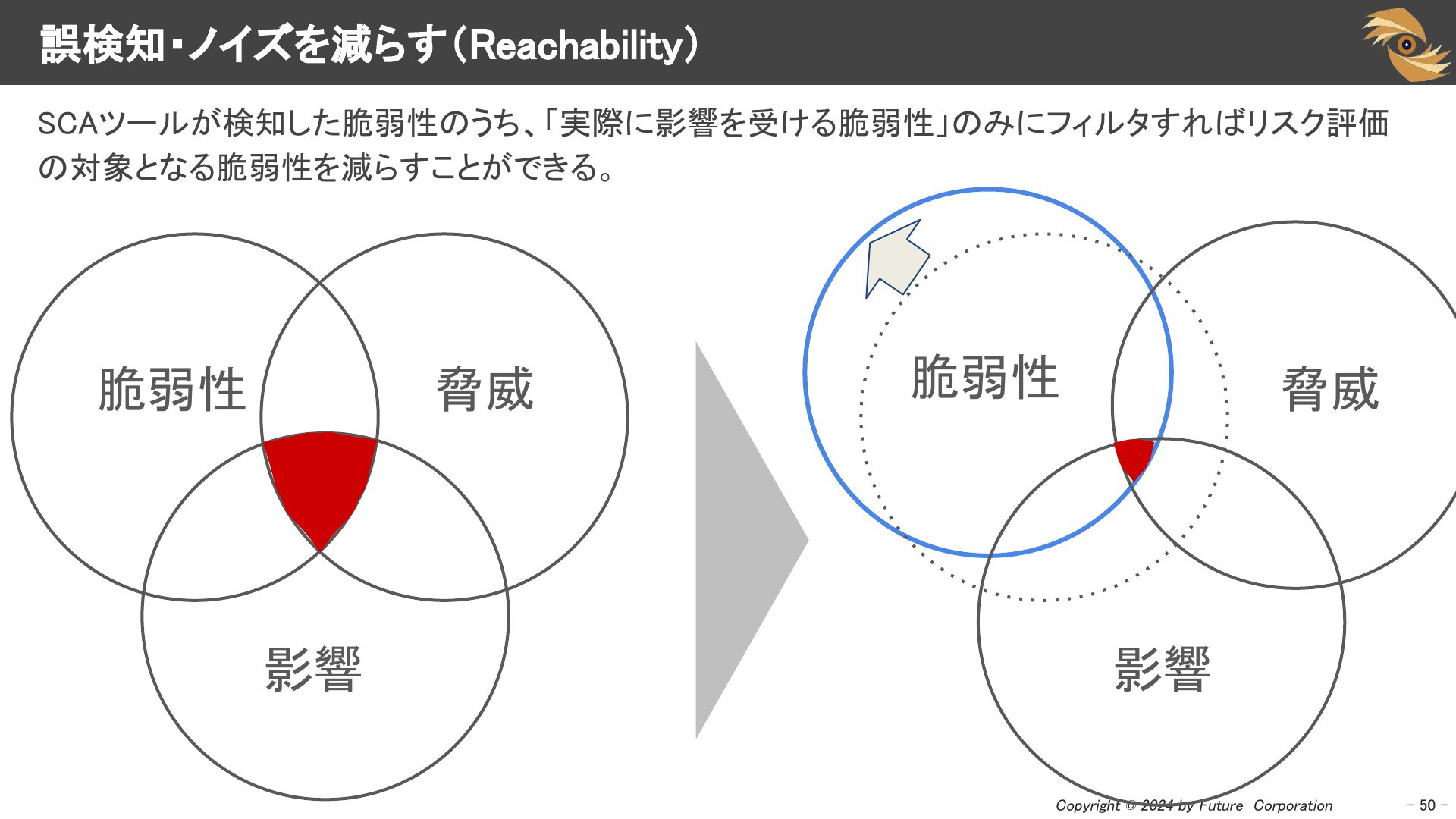
SCAツールが検知した脆弱性のうち、「実際に影響を受ける脆弱性」のみにフィルタすればリスク評価の対象となる脆弱性を減らすことができます。
ツールが検知した脆弱性の誤検知率
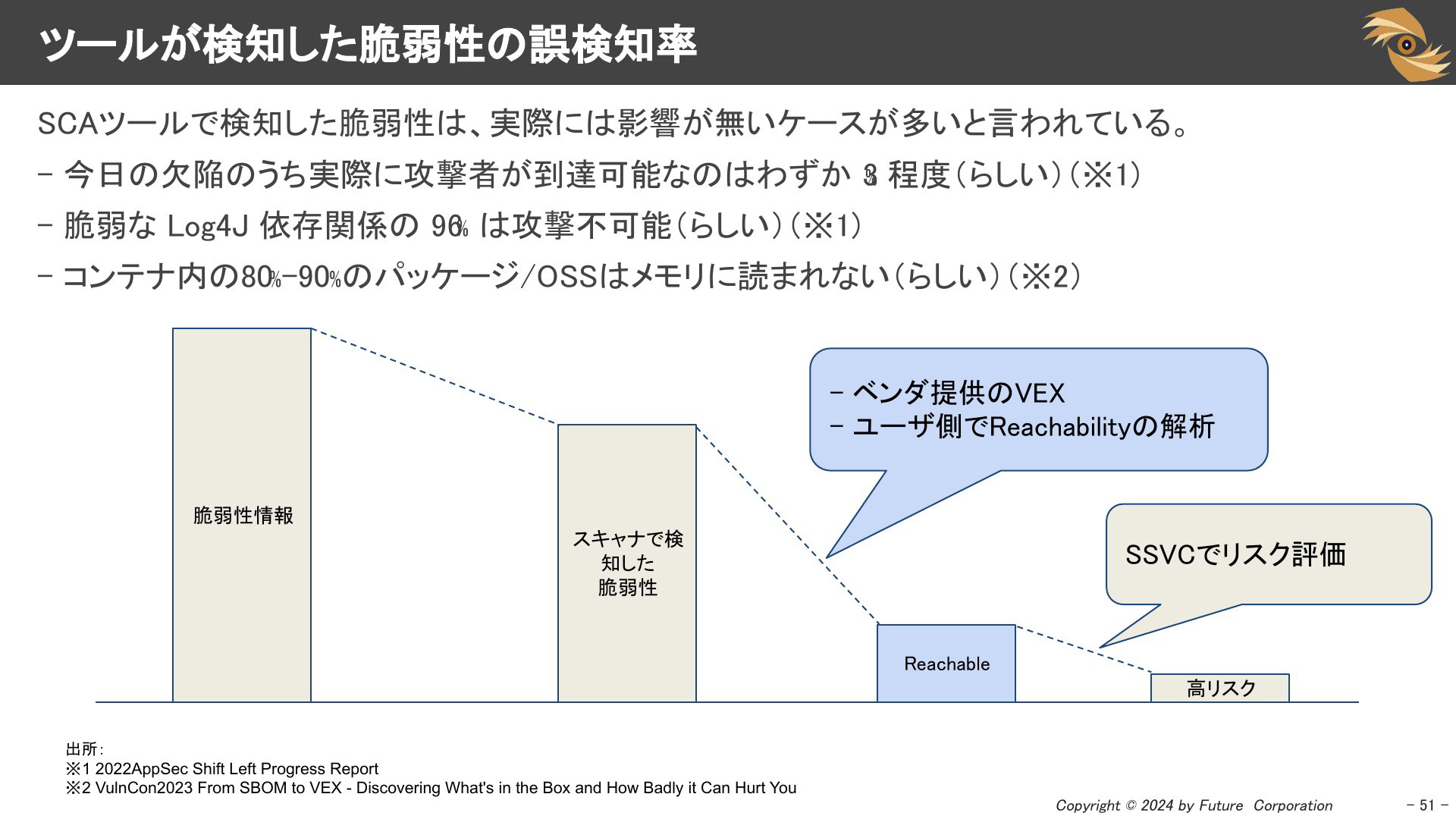
SCAツールで検知した脆弱性は、実際には影響が無いケースが多いと言われている。
- 今日の欠陥のうち実際に攻撃者が到達可能なのはわずか 3% 程度(らしい)
- 脆弱な Log4J 依存関係の 96% は攻撃不可能(らしい)
- コンテナ内の80%-90%のパッケージ/OSSはメモリに読まれない(らしい)
2.1 ベンダー/OSSが提供するVEXを利用する

Vulnerability Exploitability eXchange(VEX)
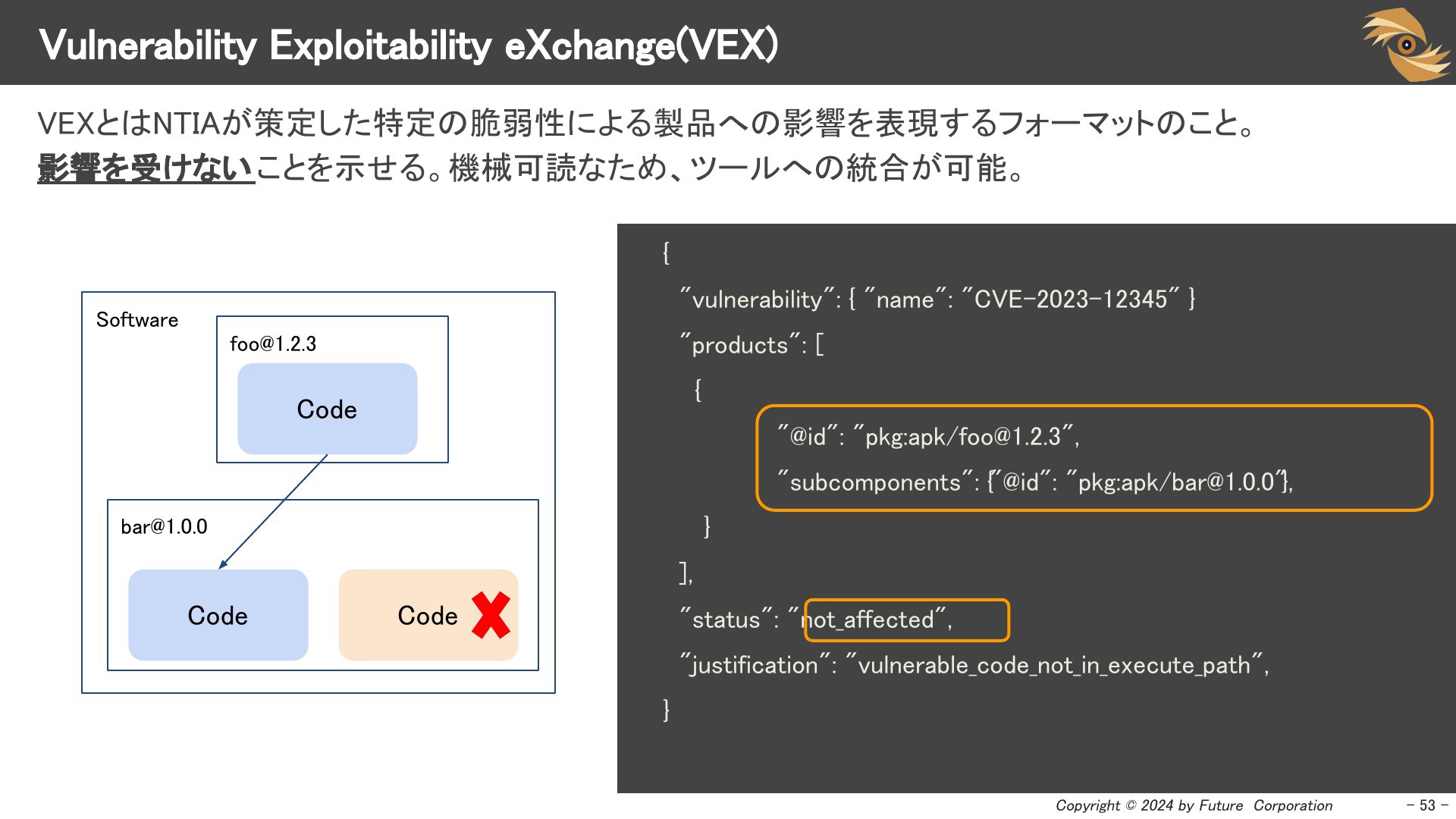
VEXとはNTIAが策定した特定の脆弱性による製品への影響を表現するフォーマットのことです。
機械可読なため、ツールへの統合が可能です。右側の例では、ツールとしては検知されてしまいますが、脆弱な関数を呼び出していないため、実際には影響を受けないことを示せます。
VEXによりReachableな脆弱性のみにフィルタ可能
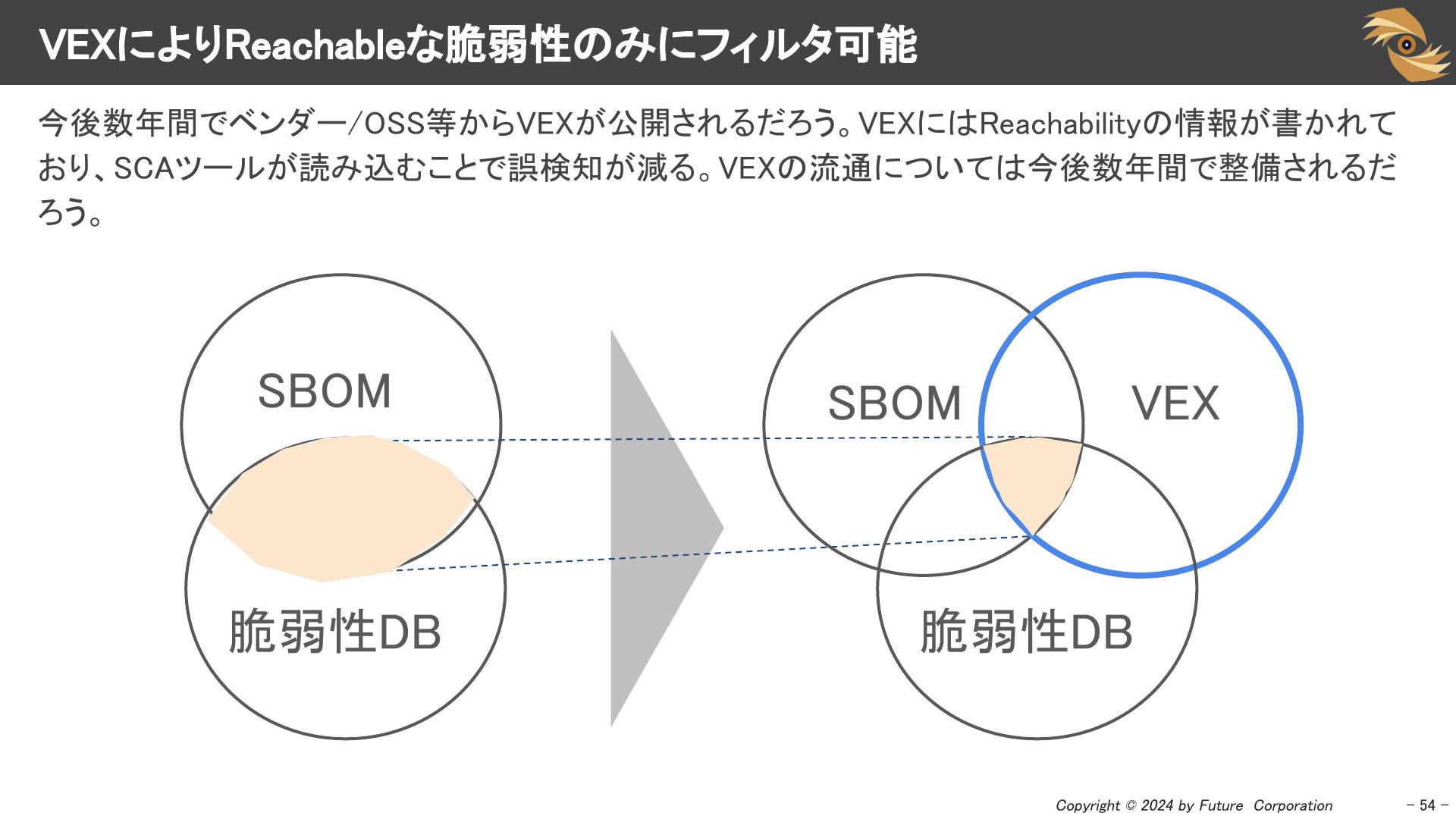
今後数年間でベンダー/OSS等からVEXが公開されるでしょう。VEXにはReachabilityの情報が書かれており、SCAツールが読み込むことで誤検知を減らせます。VEXの流通については以下の課題があり現在議論中ですが、今後数年間で整備されるでしょう。
- VEXファイルの集約方法と場所
- 中央集約型のリポジトリにするか分散型にするか
- SBOMとの連携方法(VEXの参照をどうするか)
- 既存SCAツールとの連携をどうするか
Trivyはいち早くVEXの置き場所を実装しています。aquasecurity/vexhubに配置されたVEXファイルをTrivyから参照し、Reachabilityを判別し、検知結果から影響のないものをフィルタする機能を実装しています。
2.2 ユーザ側でReachabilityを検証する

ユーザ側でReachabilityを検証する

今後数年間で徐々に提供されはじめる、ベンダー/OSSから公開されるVEXのReachability情報を気長に待っていられません。
すでにいくつかReachabilityを検証しSCAツールの誤検知をフィルタする研究やツールが存在します。
いくつか紹介します。
CSS2024一般論文セッションに提出された以下の論文は、SCAツールで検知された脆弱性中から、実際に利用されているLinuxカーネルモジュールや、Windowsサービスのみにフィルタするという研究です。
- PSIRT向け脆弱性スクリーニング技術と環境毎リスク評価技術 (OWSトラック)
- 金井 遵 (東芝), 上原 龍也 (東芝), 小池 竜一 (東芝), 鬼頭 利之 (東芝), 神戸 康多 (フューチャー), 木戸 俊輔 (フューチャー), 篠原 俊一 (フューチャー), 中岡 典弘 (フューチャー), 林 優二郎 (フューチャー)
govulncheckは、Go公式の脆弱性検知ツールです。Go公式の脆弱性データベース側で脆弱な関数の情報が定義されています。静的解析の結果、脆弱なシンボル・関数を内部で呼び出しているかをチェックすることで、Reachabilityを判断します。
また、Kubescapeは、eBPFを用いて読み込まれたファイルのパスの情報によりReachabilityを判断します。
これらの研究やツールのように今後様々な研究やツールが生み出されると予想しています。
まとめ
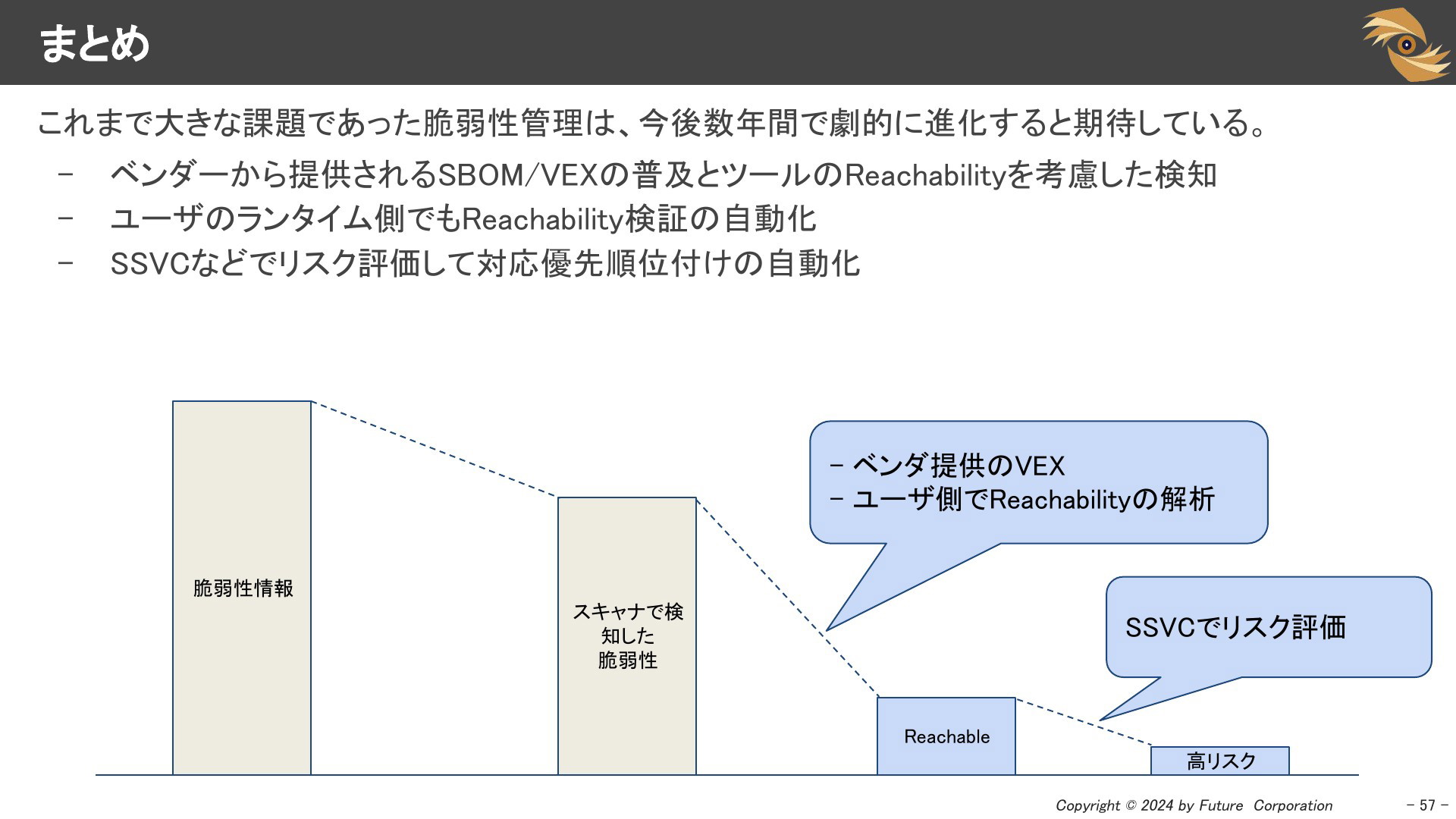
これまで大きな課題であった脆弱性管理は、今後数年間で劇的に進化すると期待しています。
- ベンダーから提供されるSBOM/VEXの普及とツールのReachabilityを考慮した検知
- ユーザのランタイム側でもReachability検証の自動化
- SSVCなどでリスク評価して対応優先順位付けの自動化
最後に
SSVCを用いた脆弱性管理の自動化に興味がある方は「FutureVulsのLP」からぜひお問い合わせください。